Skapa buffertar
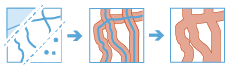
En buffert är ett område som täcker ett givet avstånd från ett punkt-, linje- eller områdesgeoobjekt.
Buffertar används normalt sett för att skapa områden som kan analyseras ytterligare med andra verktyg. Om frågan till exempel är "Vilka byggnader ligger inom en kilometer från skolan?", kan du hitta svaret genom att skapa en buffert på en kilometer kring skolan och sedan överlagra bufferten med det lager som innehåller byggnadsavtrycken. Slutresultatet blir ett lager med de byggnader som ligger inom en kilometer från skolan.
Välj lager att tillämpa buffert på
Det punkt-, linje- eller områdesgeoobjekt som ska bilda bufferten. Indatalager måste finnas i ett projicerat koordinatsystem eller så måste den geografiska referensen för bearbetning ställas in för ett projicerat koordinatsystem med Analysmiljö.
Förutom att välja ett lager från kartan kan du välja Välj analyslager längst ned i listrutan för att bläddra till ditt innehåll efter ett big data-fildelningsdataset eller geoobjektlager.
Välj typ av buffert att tillämpa
Det finns tre sätt du kan ange buffertstorleken för dina indatageoobjekt:
- Ange ett avstånd som ska tillämpas för alla geoobjekt.
- Ange ett fält på indatalagret som innehåller avståndsvärdet. Du kan använda ett strängfält eller ett numeriskt fält. Om ingen linjär enhet är definierad används enheterna i den geografiska referensen. Om du använder ett geografiskt koordinatsystem antas det enhetslösa fältet vara meter.
- Skapa ett uttryck med flera fält och matematiska operatorer. Om du till exempel vill tillämpa en buffert på 10 gånger värdet för ett fält med namnet wind_speed lägger du till uttrycket $feature["wind_speed"] x 10.
Välj buffertmetod
Du kan använda en Plan metod eller en Geodetisk metod. Den Plana metoden kan vara snabbare och lämpar sig för lokal analys på projicerade data. Den geodetiska metoden lämpar sig för stora ytor och alla geografiska koordinatsystem.
Välj typ av metod för att lösa upp
Alternativ för att ange metod för att lösa upp. Om en metod för att lösa upp har valts får du alternativet att skapa flerdels- eller enkeldelsområden och kan beräkna statistik utifrån de fält som tillhandahålls.
- Alla – Alla geoobjekt löses upp. Om flerdelade geoobjekt tillåts upplöses alla geoobjekt till ett enda geoobjekt. Om flerdelade geoobjekt inte tillåts löses intilliggande eller överlappande geoobjekt upp.
- Fält – Geoobjekt som delar samma angivna fält eller fältkombination löses upp. Om flerdelade geoobjekt tillåts upplöses alla geoobjekt med samma fält till ett enda geoobjekt. Om flerdelade geoobjekt inte tillåts löses intilliggande eller överlappande geoobjekt med samma fältvärde upp.
- Inga – Inga geoobjekt löses upp. Det här är standardinställningen.
Tillåt flerdelade geoobjekt
Alternativ för att ange om resultatet ska bestå av endelade eller flerdelade geoobjekt.
- Markerat – Resultaten av analysen innehåller flerdelade geoobjekt.
- Omarkerat – Resultaten av analysen innehåller endelade geoobjekt. Det här är standardinställningen.
Lägg till statistik (valfritt)
Du kan beräkna statistik på summerade geoobjekt. Du kan beräkna följande på numeriska fält:
- Antal – Beräknar antal värden som inte är null. Kan användas på numeriska fält eller strängar. Antalet för [null, 0, 2] är 2.
- Summa – Summan av de numeriska värdena i ett fält. Summan för [null, null, 3] är 3.
- Medelvärde – Medelvärdet för numeriska värden. Medelvärde för [0, 2, null] är 1.
- Min – Minimivärdet för ett numeriskt fält. Minimivärde för [0, 2, null] är 0.
- Max – Det maximala värdet för ett numeriskt fält. Det maximala värdet för [0, 2, null] är 2.
- Intervall – Intervallet för ett numeriskt fält. Det beräknas som det maximala värdet minus minimivärdena. Intervallet för [0, null, 1] är 1. Intervallet för [null, 4] är 0.
- Varians – Variansen hos ett numeriskt fält i ett spår. Variansen hos [1] är null. Variansen hos [null, 1,0,1,1] är 0,25.
- Standardavvikelse – Standardavvikelsen hos ett numeriskt fält. Standardavvikelsen hos [1] är null. Standardavvikelsen hos [null, 1,0,1,1] är 0,5.
Du kan beräkna följande på numeriska fält:
- Antal – Antalet strängar som inte är null.
- Alla – Det statistiska värdet är ett slumpmässigt exempel på ett strängvärde i det angivna fältet.
Välj ett ArcGIS-datalager att spara resultat till
GeoAnalytics-resultat sparas i ett datalager och visas som ett geoobjektlager i Portal for ArcGIS. I de flesta fall ska resultat sparas i det rumstemporala datalagret och det är standardinställningen. I vissa fall är det ett bra alternativ att spara resultat i det relationella datalagret. Följande är anledningar till varför du kanske vill spara resultat i det relationella datalagret:
- Du kan använda resultaten i portal-till-portal-samarbeten.
- Du kan aktivera synkroniseringsfunktioner med dina resultat.
Du bör inte använda det relationella datalagret om du förväntar dig att dina GeoAnalytics-resultat kommer att öka och du behöver använda det rumstemporala big data-lagrets funktioner till att hantera stora mängder data.
Resultatlagrets namn
Namnet på lagret som ska skapas. Om du skriver till en ArcGIS Data Store, sparas dina resultat i Mitt innehåll och läggs till i kartan. Om du skriver till en big data-fildelning, lagras dina resultat i big data-fildelningen och läggs till i dess manifest. Det läggs inte till i kartan. Standardnamnet baseras på verktygets namn och indatalagrets namn. Om lagret redan finns misslyckas verktyget.
När du skriver till ArcGIS Data Store (relationellt eller rumstemporärt Big Data-datalager) med listrutan Spara resultat i kan du ange namnet på en mapp i Mitt innehåll där resultatet ska sparas.