Reconstruir Trilhos
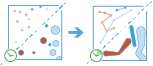
Esta ferramenta funciona com uma camada com componente temporal ativa, quer de elementos de ponto ou área, que representam um instante no tempo. Primeiro, determina que elementos pertencem a um trilho utilizando um identificador. Utilizando o tempo em cada localização, os trilhos são ordenados sequencialmente e transformados numa linha ou área representando o percurso do movimento ao longo do tempo. Opcionalmente, a entrada pode ser colocada em memória intermédia por um campo, o que criará uma área em cada local. Estes pontos ou áreas de entrada colocados em memória intermédia, são, então, ligados sequencialmente para criar um trilho como uma área em que a largura é representativa do atributo de interesse. Os trilhos resultantes têm uma hora de início e de fim, que representam, em termos temporais, o primeiro e o último elemento num dado trilho. Quando os trilhos são criados, são calculadas estatísticas sobre os elementos de entrada, e atribuídas ao trilho de saída. A estatística mais básica é a contagem do número de pontos dentro da área, mas também pode calcular outras estatísticas.
Os elementos, em camadas com componente temporal ativa, podem ser representados de duas formas:
- Instante—um momento único no tempo
- Intervalo—Uma hora de início e de fim
Por exemplo, suponha que tem medições de GPS de furacões a cada 10 minutos. Cada medição de GPS regista o nome e localização do furacão, hora da gravação e a velocidade do vento. Com estas informações, poderia criar trilhos para cada furacão, utilizando o nome para identificação de trilho, e seriam gerados trilhos para cada furacão. Adicionalmente, poderia calcular estatísticas, tais como a velocidade do vento média, máxima e mínima de cada furacão, bem como a contagem de medições incluídas em cada trilho.
Utilizando os mesmos exemplos, poderia aplicar buffer aos seus trilhos com base na velocidade do vento. Isto iria colocar em memória intermédia cada medição, com base no campo velocidade do vento nessa localização, e juntar as áreas colocadas na memória intermédia, criando uma área representativa do percurso do trilho, bem como as alterações à velocidade do vento, à medida que os furacões progridem.
Selecionar elementos a partir dos quais reconstruir trilhos
A camada de pontos ou áreas que será reconstruída em trilhos. A camada de entrada tem de ter a componente temporal ativa com elementos que representam um momento no tempo. A camada tem de encontrar-se num sistema de coordenadas projetado ou a referência espacial de processamento tem de ser definida para um sistema de coordenadas projetado que utilize os Ambientes de Análise no caso de ser aplicado um buffer.
Para além de escolher uma camada do seu mapa, pode escolher Escolher Camada de Análise na parte inferior da lista pendente para navegar até aos seus conteúdos de um conjunto de dados de partilha de ficheiros de big data ou camada de elementos.
Selecionar um ou mais campos nos quais identificar trilhos
Os campos que representam o identificador de trilhos.
Como exemplo, caso estivesse a reconstruir trilhos de furacões, poderia utilizar os nomes dos furacões como campo de trilho.
Selecionar método utilizado para reconstruir trilhos
Método utilizado para ligar trilhos e aplicar buffer (se aplicável). O método Planar pode calcular os resultados mais rapidamente, mas não irá associar os trilhos à linha de data internacional, ou considerar o verdadeiro formato da Terra, ao aplicar buffers. O método Geodésico irá associar os trilhos à linha de data internacional, se necessário, e aplicar um buffer geodésico para considerar o formato da Terra.
Criar uma expressão para criar buffer de elementos de entrada (opcional)
Equação utilizada para calcular a distância de buffer em torno de elementos de entrada. Esta equação pode ser gerada utilizando a calculadora de buffer e operações básicas, como adicionar, subtrair, multiplicar e dividir são suportadas. Os valores são calculados utilizando o sistema de coordenadas da análise. A camada tem de encontrar-se num sistema de coordenadas projetado ou a referência espacial de processamento tem de ser definida para um sistema de coordenadas projetado que utilize os Ambientes de Análise no caso de ser aplicado um buffer.
Uma equação como $feature.windspeed * 1000 aplicariaia um buffer de 1000 multiplicado pelo campo windspeed. Pode utilizar mais do que um campo na calculadora de buffer.
Também pode especificar uma expressão com a função de trilhos ativada. Por exemplo, pode calcular a soma do valor de campo windspeed para o atual elemento e os dois ateriores elementos com uma equação como $track.field(windspeed).history(-3). Em cada local, a soma de windspeedatual, e as duas medições anteriores seria calculada e ser-lhe-ia aplicado um buffer.
Selecionar um tempo pelo qual dividir trilhos (opcional)
Hora utilizada para dividir trilhos. Se pontos ou áreas de entrada tiverem uma duração mais longa entre eles do que a divisão de tempo, então, serão separados para trilhos diferentes.
Caso especifique uma divisão temporal e uma divisão de distância, os trilhos serão divididos quando uma ou ambas as condições forem correspondidas.
Imagine que tem elementos de ponto que representam voos de aviões, em que o campo do trilho é a ID do avião. Este avião poderia efetuar várias viagens e seria representado como um trilho. Caso soubesse que existe uma pausa de de 1 hora entre os voos, poderia utilizar 1 hora como a sua divisão de trilhos, e cada voo seria atribuído ao seu respetivo trilho.
Divisão de Trilhos (opcional)
É possível dividir os trilhos utilizando três métodos diferentes. Pode usar-se uma combinação de nenhum, todos ou alguns métodos de divisão.
As divisões podem ser criadas das seguintes maneiras:
- Baseado na distância entre entradas – Se existir uma distância maior entre pontos ou áreas de entrada do que a distância especificada, então, estes serão divididos em trilhos diferentes. Por exemplo, se especificou uma distância de 10 quilómetros, pontos sequenciais maiores do que 10 quilómetros estariam em trilhos separados.
- Baseado no tempo entre entradas - Se pontos ou áreas de entrada tiverem uma duração mais elevada entre eles do que a separação temporal, então, serão separados para trilhos diferentes. Por exemplo, se tiver elementos de ponto que representem voos de aviões, em que o campo do trilho é o ID do avião. Este avião poderia efetuar várias viagens e seria representado como um trilho. Caso soubesse que existe uma pausa de de 1 hora entre os voos, poderia utilizar
1 horacomo a sua divisão de trilhos, e cada voo seria atribuído ao seu respetivo trilho. - Em tempos de intervalo definidos– Separação utilizando intervalos regulares, especificados por um intervalo de tempo e um tempo de referência. Se não especificar um momento de referência, será utilizado 1 de janeiro de 1970. Por exemplo, se especificou 1 ano com um momento de referência de 2 de fevereiro de 1990 às 10:00, então dividirá trilhos em 2 de fevereiro de 1990 às 10:00, 2 de fevereiro de 1991 às 10:00 e continuará em intervalos anuais.
Se especificar múltiplas opções de separação, os trilhos serão divididos quando uma ou mais condições forem satisfeitas.
Selecionar uma distância pela qual dividir trilhos (opcional)
Utilizar a distância para dividir trilhos. Se existir uma distância maior entre pontos ou áreas de entrada do que a separação da distância, então, estes serão divididos para trilhos diferentes.
Caso especifique uma divisão temporal e uma divisão de distância, os trilhos serão divididos quando uma ou ambas as condições forem correspondidas.
Adicionar estatísticas (opcional)
Pode calcular estatísticas em elementos que se encontram resumidos. Pode calcular os seguintes em campos numéricos:
- Contagem—Calcula o número de valores não-nulos. Pode ser utilizado em campos numéricos ou em strings. A contagem de [null, 0, 2] é 2.
- Soma—A soma dos valores numéricos num campo. A soma de [null, null, 3] é 3.
- Média—A média de valores numéricos. A média de [0, 2, null] é 1.
- Mín—o valor mínimo de um campo numérico. O mínimo de [0, 2, null] é 0.
- Máx—o valor máximo de um campo numérico. O valor máximo de [0, 2, null] é 2.
- Intervalo—o intervalo de um campo numérico. Este é calculado subtraindo os valores mínimos ao valor máximo. O intervalo de [0, null, 1] é 1. O intervalo de [null, 4] é 0.
- Variância—a variância de um campo numérico num trilho. A variância de [1] é null. A variância de [null, 1,0,1] é 0.25.
- Desvio padrão—O desvio padrão de um campo numérico. O desvio padrão de [1] é null. O desvio padrão de [null, 1,0,1,1] é 0.5.
Pode calcular os seguintes em campos de string:
- Contagem—O número de strings não-nulas.
- Qualquer—Esta estatística é uma amostra aleatória de um valor de string no campo especificado.
Selecionar um ArcGIS Data Store no qual guardar os resultados
Os resultados de GeoAnalytics são guardados num armazenamento de dados e expostos como uma camada de elementos em Portal for ArcGIS. Na maioria dos casos, os resultados deverão ser armazenados num armazenamento de dados espaciotemporal, sendo este o comportamento predefinido. Em alguns casos, será uma boa opção guardar os resultados no armazenamento de dados relacional. As seguintes são razões que justificam o armazenamento de resultados no armazenamento de dados relacional.
- Pode utilizar resultados em colaboração portal-to-portal.
- Pode ativar funcionalidades de sincronização com os seus resultados
Não deverá utilizar o armazenamento de dados relacional caso antecipe um aumento dos seus resultados de GeoAnalytics e necessite de tirar partido das funcionalidades de armazenamento de big data espaciotemporais para gerir grandes quantidades de dados.
Nome da camada resultante
O nome da camada que será criada. Se estiver a escrever para ArcGIS Data Store, os seus resultados serão gravados em O Meu Conteúdo e adicionados ao mapa. Se estiver a escrever para uma partilha de ficheiros big data, os seus resultados serão guardados numa partilha de ficheiros big data e adicionados ao seu manifesto. Não serão adicionados ao mapa. O nome padrão é baseado no nome da ferramenta e do nome da camada de entrada. Caso a camada já existe, a ferramenta irá falhar.
Ao escrever para ArcGIS Data Store (armazenamento relacional ou espaciotemporal de dados big data) utilizando a caixa suspensa Guardar resultado em pode especificar o nome de uma pasta em O Meu Conteúdo, onde será armazenado o resultado.