Localizar Valor Alto de Incidência
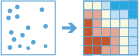
A ferramenta Localizar Valor Alto de Incidência determinará se existe qualquer agrupamento estatisticamente significativo no modelo espacial dos seus dados.
- Seus pontos estão (incidentes de crimes, árvores, acidentes de tráfego) realmente agrupados? Como você pode estar certo?
- Você realmente descobriu um valor alto de incidência estatisticamente significativo, ou seu mapa contará uma história diferente se você mudou a forma como ele foi simbolizado?
Até os modelos espaciais aleatórios exibem um grau de agrupamento. Além disso, nossos olhos e cérebro naturalmente tentam encontrar modelos mesmo quando não existe nenhum. Consequentemente, pode ser difícil saber se os modelos em seus dados são o resultado dos processos espaciais reais no trabalho ou apenas o resultado da alteração aleatória. Isto é devido ao fato dos pesquisadores e analistas utilizarem métodos de estatística como Localizar Valor Alto de Incidência (Getis-Ord Gi*) para quantificar modelos espaciais. Quando você localiza um agrupamento estatisticamente significativo em seus dados, você tem informações valiosas. Saber onde e quando ocorre um agrupamento pode fornecer pistas importantes sobre os processos promovendo os modelos que você está vendo. Saber que roubos residenciais, por exemplo, são constantemente mais altos em determinados bairros é uma informação vital se você precisar projetar estratégias de prevenção efetivas, alocar recursos de polícia escassos, iniciar programas de cuidados da vizinhança, autorizar investigações criminais detalhadas ou identificar potenciais suspeitos.
Escolha a camada para a qual os valores altos de incidência serão calculados
A camada de ponto da qual os valores altos e baixos de incidêmcia serão localizados.
Esta análise utiliza caixas e exige um sistema de coordenadas plana. Você pode configurar o Processamento de sistema de coordenadas nos Ambientes de Análise. Se seu processamento de sistema de coordenadas não estiver configurado para um sistema de coordenada plana, você será solicitado para definí-lo quando você Executar Análise .
Além de escolher uma camada do seu mapa, você pode selecionar Escolher Camada de Análise na parte inferior da lista suspensa para procurar por seu conteúdo para um conjunto de dados de compartilhamento do arquivo de grandes dados ou camada de feição.
Localizar agrupamentos de valores altos e baixos
Esta análise responde a pergunta: Onde há agrupamento espaciais de valores altos e baixos?
Se os seus dados forem de pontos e você escolher Contagens de Ponto, esta ferramenta avaliará a disposição espacial das feições de ponto para responder a pergunta: Onde os pontos são inesperadamente agrupados ou separados?
Se você escolher um campo, esta ferramenta avaliará a disposição espacial dos valores associados com cada feição para responder a pergunta: Onde estão os agrupamentos de valores altos e baixos?
Selecione o tamanho da caixa para agregação
A distância utilizada para gerar bins quadrados que serão utilizados para analisar seus pontos de entrada.
Localizar ponto ativo utilizando intervalos de tempo (opcional)
Se o tempo estiver habilitado na camada de ponto, e for do tipo instantâneo, você poderá analisar utilizando intervalos de tempo.
Intervalo de tempo
Intervalo de tempo utilizado para gerar intervalos de tempo. O tempo pode ser alinhado para o tempo inicial ou final dos dados de entrada, ou para um tempo de referência especificado.
Intervalo de tempo
Intervalo de tempo utilizado para gerar intervalos de tempo. O tempo pode ser alinhado para o tempo inicial ou final dos dados de entrada, ou para um tempo de referência especificado.
Escolha como alinhar intervalos de tempo
Como intervalos de tempo são alinhados. Há três maneiras de alinhar os intervalos de tempo:
- Tempo Inicial—Os intervalos de tempo são alinhados com a primeira feição no tempo.
- Tempo Final—Os intervalos de tempo são alinhados com a última feição no tempo.
- Tempo de Referência—Os intervalos de tempo são alinhados com um tempo especificado.
Tempo de referência para alinhar intervalo de tempo
A data e hora utilizadas para alinhar os intervalos de tempo.
Selecione o tamanho da vizinhança para cálculos de ponto ativo
A distância utilizada para determinar a vizinhança utilizada para cálculos de ponto ativo. A vizinhança deve ser maior que o tamanho de bin para garantir que cada bin tenha pelo menos um vizinho. Cada bin é analisado e comparado aos bins da vizinhança.
SpatialReference (wkid)
Este é um parâmetro temporário do pré lançamento para configurar a referência de processamento espacial. Muitas ferramentas de big data exigem que um sistema de coordenada plana seja utilizada como a referência espacial para processamento. Por padrão, a ferramenta utilizará o sistema de coordenadas de entrada mas falhará se for um sistema de coordenadas geográficas. Para configurar um sistema de coordenadas plana, insira o WKID. Por exemplo, Web Mercator seria inserido como 3857.
Escolher um ArcGIS Data Store para salvar os resultados
Os resultados do GeoAnalytic são armazenados em um armazenamento de dados e expostos como uma camada de feição no Portal for ArcGIS. Na maioria dos casos, os resultados devem ser armazenados no armazenamento de dados de espaço-tempo e este é o padrão. Em alguns casos, salvar resultados no armazenamento de dados relacional é uma boa opção. Abaixo estão as razões pelas quais você talvez queira armazenar resultados em um armazenamento de dados relacional:
- Você pode utilizar os resultados no portal-para-colaboração do portal.
- Você pode habilitar os recursos de sincronização com seus resultados.
Você não deve utilizar um armazenamento de dados relacional se você espera que os resultados do GeoAnalytics aumentem e deseja aproveitar os recursos do armazenamento de grandes dados de espaço-tempo para lidar com grandes quantidades de dados.
Nome da camada resultante
O nome da camada que será criada. Se você estiver gravando em um ArcGIS Data Store, seus resultados serão salvos em Meu Conteúdo e adicionados no mapa. Se você estiver gravando em um compartilhamento do arquivo de grandes dados, seus resultados serão armazenados compartilhamento do arquivo de grandes dados e adicionados em seu manifesto. Não serão adicionados no mapa. O nome padrão é baseado no nome da ferramenta e o nome da camada de entrada. Se a camada já existe, a ferramenta falhará.
Esta camada resultante mostrará a você agrupamentos estatisticamente significativos de valores altos e baixos ou contagens de ponto. Se o nome da camada resultante já existir, você será avisado para renomeá-lo.
Ao gravar no ArcGIS Data Store (armazenamento de grandes dados de espaço-tempo ou relacional) utilizando a caixa suspensa Salvar resultados em , você pode especificar o nome de uma pasta em Meu Conteúdo onde o resultado será salvo.