Znajdź elementy odstające
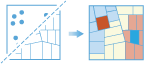
Za pomocą narzędzia Znajdź elementy odstające można sprawdzić, czy zależności przestrzenne występujące w danych zawierają statystycznie istotne elementy odstające.
- Czy w danych (dotyczących przestępstw, drzew, wypadków drogowych) występują nietypowe obszary zależności? Masz absolutną pewność?
- Czy naprawdę udało się ustalić, jakie są statystycznie istotne elementy odstające (wydatki, umieralność noworodków, systematycznie wysokie wyniki testów) czy może Twoja mapa przedstawiałaby zupełnie inne zależności, gdyby zmienione zostały używane symbole?
Gdy patrzymy na mapę, nasze oczy i mózg natychmiast zaczynają wyszukiwać zależności, nawet jeśli takie nie istnieją. W konsekwencji trudno jest ocenić, czy zależności pojawiające się w Twoich danych są wynikiem rzeczywistych procesów przestrzennych czy może losowym przypadkiem. Właśnie dlatego badacze oraz analitycy korzystają z metod statystycznych, takich jak Znajdź elementy odstające (Anselin Local Moran's I) w celu ilościowego określania zależności przestrzennych. Odnalezienie statystycznie istotnych elementów odstających lub klastrów w danych pozwala uzyskać wartościowe informacje. Dzięki wiedzy o tym, gdzie i kiedy pojawiają się elementy odstające, można lepiej poznać procesy sprzyjające powstawaniu widocznych zależności. Następnie należałoby zbadać, dlaczego obszary odstające wyraźnie się różnią. W przypadku zadań polegających na przykład na opracowaniu skutecznych strategii zapobiegania, rozlokowaniu ograniczonych sił policyjnych, wdrożeniu sąsiedzkich programów przeciwdziałania przestępczości, podjęciu decyzji o rozpoczęciu dogłębnego śledztwa kryminalnego czy identyfikacji potencjalnych podejrzanych informacja o tym, że w określonych dzielnicach znacznie częściej dochodzi do kradzieży z włamaniem, mimo że są one otoczone dzielnicami o niskim wskaźniku tego typu przestępstw, nabiera kluczowego znaczenia.
Wybierz warstwę, dla której mają zostać obliczone elementy odstające
Warstwa punktowa lub powierzchniowa, w której mają zostać znalezione elementy odstające.
Znajdź elementy odstające dla
Ta analiza odpowiada na pytanie: gdzie w moich danych znajdują się elementy odstające?
Jeśli dane są przedstawione w postaci punktów i wybrane jest narzędzie Liczba punktów, narzędzie wykona ocenę przestrzennego rozmieszczenia obiektów punktowych w celu uzyskania odpowiedzi na pytanie: Gdzie punkty te uległy nagłemu zagęszczeniu lub rozproszeniu?
Jeśli zostanie wybrane pole, to narzędzie wykona ocenę przestrzennego rozmieszczenia wartości powiązanych z każdym obiektem w celu uzyskania odpowiedzi na pytania: gdzie znajdują się niskie wartości otoczone wysokimi wartościami? Gdzie znajdują się wysokie wartości otoczone niskimi wartościami?
Liczba punktów w
Domyślnie punkty są zliczane w obrębie siatki utworzonej za pomocą narzędzia w oparciu o dane punktowe. Można również wybrać opcję zliczania punktów na siatce sześciokątnej lub wskazać warstwę powierzchniową (zwykle reprezentującą obszar administracyjny, dla którego tworzone są raporty, taki jak obwód spisowy, granice miejskie czy powiat), aby uzyskać odpowiedź na pytanie: czy, w oparciu o liczbę punktów w każdym obiekcie powierzchniowym, istnieją lokalizacje, w których liczba punktów jest istotnie wyższa lub niższa niż w lokalizacjach sąsiadujących?
Wskaż prawdopodobne miejsca punktów
Wyświetl lub wskaż warstwę definiującą możliwość wystąpienia zdarzeń, aby uzyskać odpowiedź na pytanie: czy w granicach obszarów istnieją lokalizacje o nieoczekiwanie wysokich lub niskich koncentracjach punktów?
Utworzone obiekty powierzchniowe lub obiekty w podanej warstwie obszarów powinny definiować potencjalne lokalizacje punktów. Aby wyświetlić te obszary, kliknij przycisk Wyświetl, a następnie kliknij mapę w dowolnym miejscu i utwórz kształt obszaru. Aby wyświetlić dodatkowe obszary, kliknij ponownie przycisk wyświetlania, a następnie kliknij mapę w dowolnym miejscu, aby kontynuować.
Dzielone przez
Niekiedy wymagane jest przeanalizowanie wzorów uwzględniających rozkłady podkładowe. Na przykład, jeżeli punkty reprezentują przestępstwa, to podzielenie ich liczby przez liczbę ludności pozwoli na opracowanie analizy wskaźnika przestępczości przypadającej na mieszkańca, a nie tylko przedstawienie samej liczby przestępstw. Wybór atrybutu do dzielenia jest często nazywany procesem normalizacji.
Wybranie opcji Populacja Esri pozwoli na dodanie do każdego obiektu powierzchniowego wartości liczby ludności, które następnie posłużą jako atrybut operacji dzielenia. Korzystanie z tej opcji powoduje zużywanie kredytów.
Optymalizuj dla
Można przeprowadzić optymalizację pod kątem szybkości lub dokładności.
Narzędzie to korzysta z permutacji, ustalając, w jaki sposób zależności występujące w danych różnią się od zależności przypadkowych. Zwiększenie liczby permutacji powoduje zwiększenie dokładności, ale także wydłuża czas przetwarzania.
Opcje zastępowania
Narzędzie automatycznie znajduje optymalne wartości domyślne opcji Wielkość komórki i Pasmo odległości na podstawie cech Twoich danych. Jeśli jednak w przypadku wykonywanej analizy sensowne jest użycie określonych wartości opcji Wielkość komórki lub Pasmo odległości, można je skonfigurować przy użyciu opcji Zastąp opcje.
Opcja Zastąp opcje jest także przydatna podczas analizowania innych zestawów danych, ponieważ umożliwia użycie tych samych wartości opcji Pasmo odległości i Wielkość komórki w wielu zestawach danych. Następnie można porównać wyniki (na przykład wskaźniki otyłości ze wskaźnikami występowania cukrzycy lub nawet wskaźniki przestępczości dla dwóch różnych lat).
Wielkość komórki
Wielkość komórek siatki, w których będą zliczane punkty.
W przypadku zliczania punktów w siatce sześciokątnej ta wartość jest używana jako wysokość sześciokątów.
Pasmo odległości
Każdy obiekt jest analizowany w kontekście obiektów sąsiadujących znajdujących się w obszarze o podanym promieniu. Narzędzie oblicza domyślną odległość automatycznie, ale używając tej opcji, można skonfigurować konkretną odległość, która ma sens w przypadku wykonywanej analizy.
Jeśli na przykład są badane zależności związane z dojazdami do pracy i wiadomo, że dojeżdżając do pracy pokonuje się średnio 15 mil, można użyć pasma odległości wynoszącego 15 mil.
Nazwa warstwy wynikowej
Opcja umożliwiająca określenie nazwy warstwy, która zostanie utworzona w zakładce Moje zasoby i dodana do mapy. Warstwa wynikowa będzie zawierać miejsca, w których znajdują się statystycznie istotne elementy odstające o wysokich lub niskich wartościach bądź z wysoką lub niską liczbą punktów. Jeśli nazwa warstwy wynikowej już istnieje, zostanie wyświetlony komunikat z prośbą o zmianę nazwy.
Używając listy rozwijanej Zapisz wynik w, można określić nazwę folderu w zakładce Moje zasoby, gdzie zostanie zapisany wynik.