Znajdź lokalizacje hot spot
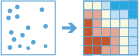
Narzędzie Znajdź lokalizacje hot spot ustala, czy w relacjach przestrzennych danych użytkownika istnieją statystycznie istotne klastry.
- Czy Twoje punkty (reprezentujące przestępstwa, drzewa lub wypadki drogowe) rzeczywiście są zgrupowane? Masz absolutną pewność?
- Czy naprawdę udało Ci się ustalić, jakie są statystycznie istotne lokalizacje hot spot czy może Twoja mapa przedstawiałaby zupełnie inne zależności, gdyby zmienione zostały użyte symbole?
Nawet losowo wybrane dane przestrzenne można w większym lub mniejszym stopniu pogrupować. Dodatkowo ludzki mózg oraz wzrok charakteryzuje naturalna tendencja do wyszukiwania zależności, nawet jeśli te nie istnieją. W konsekwencji trudno jest ocenić, czy zależności pojawiające się w Twoich danych są wynikiem rzeczywistych procesów przestrzennych czy może losowym przypadkiem. Właśnie dlatego badacze oraz analitycy korzystają z metod statystycznych, takich jak Znajdź lokalizacje hot spot (Getis-Ord Gi*) w celu ilościowego określania relacji przestrzennych. Odnalezienie statystycznie istotnych klastrów w danych pozwala uzyskać wartościowe informacje. Dzięki wiedzy o tym, gdzie i kiedy pojawiają się klastry, można lepiej poznać procesy sprzyjające powstawaniu widocznych zależności. W przypadku zadań polegających na przykład na opracowaniu skutecznych strategii zapobiegania, rozlokowaniu ograniczonych sił policyjnych, wdrożeniu sąsiedzkich programów przeciwdziałania przestępczości, podjęciu decyzji o rozpoczęciu dogłębnego śledztwa kryminalnego czy identyfikacji potencjalnych podejrzanych informacja o tym, że do kradzieży z włamaniem na terenach mieszkalnych regularnie znacznie częściej dochodzi w określonych dzielnicach, nabiera kluczowego znaczenia.
Wybierz warstwę, dla której zostaną wyznaczone lokalizacje hot spot
Warstwa punktowa, z której zostaną wyznaczone lokalizacje hot i cold spot.
Podczas wykonywania tej analizy używane są kosze i wymagany jest układ współrzędnych odwzorowanych. Układ współrzędnych przetwarzania można skonfigurować w oknie Środowiska analizy. Jeśli układ współrzędnych przetwarzania nie zostanie skonfigurowany jako układ współrzędnych odwzorowanych, podczas uruchamiania analizy zostanie wyświetlony monit informujący o konieczności wykonania tej czynności.
Oprócz wybrania warstwy z mapy, można wybrać opcję Wybierz warstwę analizy znajdującą się w dolnej części listy rozwijanej, aby przejść do zasobów zestawu danych udostępnionych plików dużych zbiorów danych lub warstwy obiektowej.
Znajdź klastry o wysokich i niskich wartościach
Analiza dostarcza odpowiedzi na pytanie: gdzie są zgrupowane przestrzennie wysokie i niskie wartości?
Jeśli dane są przedstawione w postaci punktów i wybrane jest narzędzie Liczba punktów, narzędzie wykona ocenę przestrzennego rozmieszczenia obiektów punktowych w celu uzyskania odpowiedzi na pytanie: Gdzie punkty te uległy nagłemu zagęszczeniu lub rozproszeniu?
Jeśli zostanie wybrane pole, to narzędzie wykona ocenę przestrzennego rozmieszczenia wartości powiązanych z każdym obiektem w celu uzyskania odpowiedzi na pytanie: gdzie są zgrupowane wysokie i niskie wartości?
Wybierz wielkość kosza dla agregacji
Odległość używana do generowania koszy kwadratowych, które będą używane do analizowania punktów wejściowych.
Znajdź lokalizacje hot spot z użyciem etapów czasowych (opcjonalne)
Jeśli dla warstwy punktowej włączono czas (typu Moment), można przeprowadzić analizę przy użyciu etapów czasowych.
Przedział etapu czasowego
Interwał czasu używany do tworzenia etapów czasowych. Czas można wyrównać w taki sposób, aby odpowiadał czasowi rozpoczęcia i zakończenia danych wejściowych lub podanemu czasowi referencyjnemu.
Przedział etapu czasowego
Interwał czasu używany do tworzenia etapów czasowych. Czas można wyrównać w taki sposób, aby odpowiadał czasowi rozpoczęcia i zakończenia danych wejściowych lub podanemu czasowi referencyjnemu.
Wybierz sposób wyrównania etapów czasowych
Jak wyrównywane są etapy czasowe. Istnieją trzy sposoby wyrównywania etapów czasowych:
- Czas rozpoczęcia — etapy czasowe są wyrównywane względem pierwszego obiektu w czasie.
- Czas zakończenia — etapy czasowe są wyrównywane względem ostatniego obiektu w czasie.
- Czas referencyjny — etapy czasowe są wyrównywane względem podanego czasu.
Czas referencyjny użyty do wyrównania etapów czasowych
Data i czas używane do wyrównania etapów czasowych.
Wybierz wielkość sąsiedztwa na potrzeby obliczeń lokalizacji hot spot
Odległość służąca do ustalania sąsiedztwa używanego podczas obliczeń dotyczących lokalizacji hot spot. Sąsiedztwo powinno być większe niż wielkość kosza, aby zapewnić, że każdy kosz ma co najmniej jeden kosz sąsiadujący. Każdy kosz jest analizowany i porównywany z sąsiednimi koszami.
Odniesienie przestrzenne (wkid)
Jest to parametr tymczasowy używany w wersji wstępnej do ustawiania odniesienia przestrzennego przetwarzania. Wiele narzędzi do obsługi dużych zbiorów danych wymaga użycia układu współrzędnych odwzorowanych jako odniesienia przestrzennego przetwarzania. Domyślnie narzędzie użyje wejściowego układu współrzędnych, ale operacja nie powiedzie się, jeśli będzie to układ współrzędnych geograficznych. Aby ustawić układ współrzędnych odwzorowanych, wprowadź wartość WKID. Na przykład Web Mercator zostanie wprowadzony jako 3857.
Wybierz aplikację ArcGIS Data Store, w której zostaną zapisane wyniki
Wyniki analiz geoprzestrzennych są przechowywane w magazynie danych i udostępniane jako warstwa obiektowa w witrynie Portal for ArcGIS. W większości przypadków wyniki powinny być przechowywane w magazynie danych czasowo-przestrzennych i jest to ustawienie domyślne. W niektórych przypadkach dobrym rozwiązaniem jest zapisanie wyników w relacyjnym magazynie danych. Poniżej podano sytuacje, które mogą uzasadniać przechowywanie wyników w relacyjnym magazynie danych:
- Wyniki mogą być używane w ramach kooperacji między portalami.
- Została włączona możliwość synchronizacji wyników.
Nie należy używać relacyjnego magazynu danych, jeśli liczba wyników analiz geoprzestrzennych może się zwiększyć i może być konieczne zastosowanie magazynu dużych zbiorów danych czasowo-przestrzennych w celu obsłużenia dużych ilości danych.
Nazwa warstwy wynikowej
Nazwa warstwy, która zostanie utworzona w oknie Moje zasoby. W przypadku zapisywania w ArcGIS Data Store wyniki będą przechowywane w obszarze Moje zasoby i dodawane do mapy. W przypadku zapisywania w udostępnionym pliku dużych zbiorów danych wyniki będą przechowywane w udostępnionym pliku dużych zbiorów danych i dodawane do jego manifestu. Nie będą dodawane do mapy. Nazwa domyślna jest tworzona w oparciu o nazwę narzędzia i nazwę warstwy wejściowej. Jeśli warstwa już istnieje, działanie narzędzia nie powiedzie się.
Warstwa wynikowa będzie przedstawiać miejsca, w których znajdują się statystycznie istotne zgrupowania o wysokich lub niskich wartościach bądź z wysoką lub niską liczbą punktów. Jeśli nazwa warstwy wynikowej już istnieje, zostanie wyświetlony komunikat z prośbą o zmianę nazwy.
W przypadku zapisywania w ArcGIS Data Store (relacyjny magazyn danych lub magazyn dużych zbiorów danych czasowo-przestrzennych) przy użyciu listy rozwijanej Zapisz wynik w można określić nazwę folderu w obszarze Moje zasoby, gdzie zostanie zapisany wynik.