Puntclusters zoeken
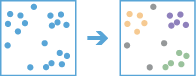
Het Puntclusters zoeken tool zoekt clusters van puntobjecten binnen omringend geluid gebaseerd op hun ruimtelijke distributie.
Een niet-gouvernementele organisatie bestudeert bijvoorbeeld een bepaalde door plagen overgedragen ziekte. Het heeft een puntdataset van huishoudens in een studiegebied, waarvan sommige wel en andere niet besmet zijn. Door de Puntclusters zoeken tool te gebruiken, kan een analist clusters van besmette huishoudens bepalen om een gebied aan te wijzen waar met de behandeling en uitroeiing van plagen kan worden begonnen.
Kies de laag waarvoor clusters zullen worden gevonden
De puntenlaag waarin clusters zich bevinden. Lagen moeten in een geprojecteerd ruimtelijke referentie of de processing ruimtelijke referentie moet worden ingesteld op een geprojecteerd coördinaatsysteem met behulp van de Analysis Environments.
Naast het kiezen van een laag van uw kaart, kunt u kiezen voor Analyselaag kiezen onderaan de keuzelijst om in uw inhoud te zoeken naar een big data file share-dataset of objectlaag.
Kies welke clustermethode u wilt gebruiken
De clusteringmethode die wordt gebruikt om clusters van puntobjecten te onderscheiden van omringende ruis. U kunt ervoor kiezen om een gedefinieerde afstands- of zelfaanpassend clusteringalgoritme te gebruiken.
Gedefinieerde afstand (DBSCAN) gebruikt een gespecificeerd zoekbereik om dichte clusters te scheiden van verspreide ruis. Gedefinieerde afstand (DBSCAN) is sneller, maar is alleen geschikt als er een zeer duidelijk zoekbereik is dat goed werkt om alle aanwezige clusters te definiëren. Gedefinieerde afstand (DBSCAN) vindt clusters met vergelijkbare dichtheden.
Zelfaanpassend (HDBSCAN) vereist geen zoekbereik dat moet worden gespecificeerd, maar het is een meer tijdrovende methode. Zelfaanpassend (HDBSCAN) vindt clusters van punten die lijken op de gedefinieerde afstand (DBSCAN), maar gebruikt verschillende zoekbereiken die clusters met verschillende dichtheden mogelijk maken.
Minimumaantal punten dat als een cluster moet worden beschouwd
Deze parameter wordt op verschillende manieren gebruikt, afhankelijk van de gekozen clusteringmethode:
- Gedefinieerde afstand (DBSCAN)—specificeert het aantal objecten dat moet worden gevonden binnen een bepaalde afstand van een punt om een cluster met dat punt te vormen. De afstand wordt gedefinieerd met behulp van de parameter Beperken tot zoekbereik.
- Zelfaanpassend (HDBSCAN)—specificeert het aantal objecten naast elk punt (inclusief het punt zelf) dat in overweging wordt genomen bij het schatten van de dichtheid. Dit aantal is ook de minimale clustergrootte die is toegestaan bij het exporteren van clusters.
Beperk het zoekbereik tot
Bij gebruik van de gedefinieerde afstand (DBSCAN) is deze parameter de afstand waarbinnen het minimumaantal punten dat als een cluster moet worden beschouwd, moet worden gevonden. Deze parameter wordt niet gebruikt wanneer zelfregulering (HDBSCAN) wordt gekozen als de te gebruiken clusteringmethode.
Resultaat laagnaam
De naam van de laag die wordt gemaakt. Als u naar een ArcGIS Data Store, schrijft, worden uw resultaten opgeslagen in Mijn Content en toegevoegd aan de kaart. Als u naar een big data file share schrijft, worden uw resultaten opgeslagen in de big data file share en toegevoegd aan het bijhorende manifest. Ze zullen niet worden toegevoegd aan de kaart. De standaardnaam is gebaseerd op de toolnaam en de naam van de invoerlaag. Als de laag al bestaat, zal de tool falen.
Wanneer u schrijft naar ArcGIS Data Store (relationele of spatiotemporele big datastore) met behulp van de vervolgkeuzelijst Resultaat opslaan in, kunt u de naam van een map opgeven in Mijn Content, waar het resultaat wordt opgeslagen.