Hotspots zoeken
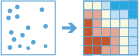
De tool Hotspots zoeken bepaalt of er sprake is van statistisch significante clustering in het ruimtelijke patroon van uw gegevens.
- Zijn uw punten (misdrijven, bomen of verkeersongevallen) echt geclusterd? Hoe zeker bent u daarvan?
- Hebt u echt een statistisch significante hotspot gevonden of zou uw kaart een ander verhaal vertellen wanneer u de symbolen ervan zou wijzigen?
Zelfs willekeurige ruimtelijke patronen vertonen een bepaald niveau van clustering. Bovendien gaan onze ogen en hersenen van nature op zoek naar patronen, zelfs wanneer deze niet bestaan. Als gevolg daarvan kan het moeilijk zijn om te bepalen of patronen in uw gegevens het resultaat zijn van echte ruimtelijke processen of gewoon het resultaat van toevalligheden. Onderzoekers en analisten gebruiken daarom statistische methoden zoals Hotspots zoeken (Getis-Ord Gi*) om ruimtelijke patronen te kwantificeren. Als u toch statistisch significante clustering in uw gegevens vindt, beschikt u over waardevolle informatie. Als u weet waar en wanneer clustering optreedt, kunt u op zoek gaan naar belangrijke hints over de processen die de patronen die u ziet, bevorderen. Als u weet dat het aantal woninginbraken bijvoorbeeld consequent hoger ligt in bepaalde buurten, beschikt u over essentiële informatie wanneer u efficiënte preventiestrategieën moet ontwikkelen, schaarse politiemiddelen moet inzetten, buurtwachten moet opzetten, diepgaande misdaadonderzoeken moet goedkeuren of mogelijke verdachten moet identificeren.
Kies de laag waarvoor de hotspots worden berekend.
De puntlaag waar hot en cold spots worden gevonden.
Deze analyse gebruikt bins en vereist een geprojecteerd coördinaatsysteem. U kunt het Processing coördinaatsysteem instellen bij Analysis Environments. Als uw huidige coördinaatsysteem niet op een geprojecteerd coördinaatsysteem is ingesteld, zal u gevraagd worden het in te stellen wanneer u Analyse uitvoeren kiest.
Naast het kiezen van een laag van uw kaart, kunt u kiezen voor Analyselaag kiezen onderaan de keuzelijst om in uw inhoud te zoeken naar een big data file share-dataset of objectlaag.
Zoek clusters van hoog en laag
Deze analyse beantwoordt de volgende vraag: Waar vormen hoge en lage waarden ruimtelijke clusters?
Als uw data bestaat uit punten en u kiest Punttellingen, zal deze tool de ruimtelijke ordening van de puntobjecten evalueren om de volgende vraag te beantwoorden: Waar zijn punten onverwacht geclusterd of uitgespreid?
Als u een veld kiest, zal deze tool de ruimtelijke ordening van de waarden geassocieerd met elk object om de vraag te beantwoorden: Waar zijn hoge en lage waarden geclusterd?
Selecteer de bingrootte voor aggregatie
De afstand gebruikt om vierkante bins te genereren die worden gebruikt om uw invoerpunten te analyseren.
Hotspots zoeken met behulp van tijdstappen (optioneel)
Als de tijd is ingeschakeld op de puntlaag en het is van het type instant, dan kunt u analyseren met behulp van tijdstappen.
Tijdstapinterval
Tijdsinterval gebruikt voor het genereren van tijdstappen. Tijd kan worden afgestemd op de begin- of eindtijd van de invoergegevens, of een opgegeven referentietijd.
Tijdstapinterval
Tijdsinterval gebruikt voor het genereren van tijdstappen. Tijd kan worden afgestemd op de begin- of eindtijd van de invoergegevens, of een opgegeven referentietijd.
Kies hoe tijdstappen uitgelijnd moeten worden
Hoe tijdstappen worden uitgelijnd. Er zijn drie manieren om tijdstappen uit te lijnen:
- Begintijd—Tijdstappen worden uitgelijnd met het eerste object in tijd.
- Eindtijd—Tijdstappen worden uitgelijnd met het laatste object in tijd.
- Referentietijd—Tijdstappen worden uitgelijnd met een opgegeven tijd.
Referentietijd om tijdstap op uit te lijnen
De datum en tijd gebruikt om tijdstappen op af te stemmen
Selecteer de buurtgrootte voor hotspotberekeningen
De afstand gebruikt om de wijk gebruikt voor hotspotberekeningen te bepalen. De buurt moet groter zijn dan de bingrootte zodat elke bin ten minste één buur heeft. Elke bin wordt geanalyseerd en vergeleken met de naburige bins.
Ruimtelijke referentie (wkid)
Dit is een tijdelijke parameter voor prerelease om de verwerkende ruimtelijke referentie in te stellen. Veel big data-tools vereisen dat er een geprojecteerd coördinatensysteem wordt gebruikt als ruimtelijke referentie voor verwerking. Standaard gebruikt de tool het invoercoördinaatsysteem maar zal falen als het een geografisch coördinaatsysteem is. Voer de WKID in om een geprojecteerd coördinaatsysteem in te stellen. Bijvoorbeeld Web Mercator worden ingevoerd als 3857.
Kies een ArcGIS Data Store om de resultaten in op te slaan
GeoAnalytic-resultaten worden opgeslagen in een datastore en weergegeven als een objectlaag in Portal for ArcGIS. In de meeste gevallen moeten de resultaten worden opgeslagen in de spatiotemporele data store en dit is de standaardinstelling. In sommige gevallen is het opslaan van de resultaten in de relationele data-opslag een goede optie. Hier volgen redenen waarom u resultaten zou willen opslaan in een relationele data-opslag:
- U kunt resultaten gebruiken in portaal-tot-portaal samenwerking.
- Om synchronisatiemogelijkheden met uw resultaten mogelijk te maken.
U moet geen gebruik maken van een relationele data-store als u verwacht dat uw GeoAnalytics-resultaten toenemen en u wilt profiteren van de mogelijkheden van de spatiotemporele big data-store om grote hoeveelheden gegevens te verwerken.
Resultaat laagnaam
De naam van de laag die wordt gemaakt. Als u naar een ArcGIS Data Store, schrijft, worden uw resultaten opgeslagen in Mijn Content en toegevoegd aan de kaart. Als u naar een big data file share schrijft, worden uw resultaten opgeslagen in de big data file share en toegevoegd aan het bijhorende manifest. Ze zullen niet worden toegevoegd aan de kaart. De standaardnaam is gebaseerd op de toolnaam en de naam van de invoerlaag. Als de laag al bestaat, zal de tool falen.
Deze resultaatlaag zal u statistisch significante clusters van hoge en lage waarden of punttellingen tonen. Als de resultaatlaag al bestaat, wordt u gevraagd er een nieuwe naam aan te geven.
Wanneer u schrijft naar ArcGIS Data Store (relationele of spatiotemporele big datastore) met behulp van de vervolgkeuzelijst Resultaat opslaan in, kunt u de naam van een map opgeven in Mijn Content, waar het resultaat wordt opgeslagen.