사건 감지(Detect Incidents)
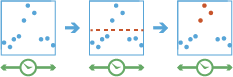
이 도구는 인스턴트 시간을 나타내는 포인트, 라인, 영역, 테이블의 시계열 레이어와 함께 작동됩니다. 이 도구는 순서가 순차적으로 지정된 피처, 즉 추적을 사용하여 어떤 피처가 관심 사건인지 파악합니다. 사건은 지정한 조건에 따라 결정됩니다.
먼저, 도구는 하나 이상의 필드를 사용하여 어떤 피처가 추적에 속하는지 결정합니다. 각 피처의 시간을 사용하여 추적 순서가 순차적으로 지정되고 사건 조건이 적용됩니다. 사건 시작 조건을 충족하는 피처가 사건으로 표시됩니다. 필요에 따라 사건 종료 조건을 적용할 수 있습니다. 종료 조건이 true인 경우 피처는 더 이상 사건이 아닙니다. 결과는 사건 이름을 나타내는 새 열을 가진 기존 피처로 반환되고 어떤 피처가 사건 조건을 충족하는지 표시됩니다. 모든 기존 피처 또는 사건인 피처만 반환할 수 있습니다.
예를 들어 10분 간격의 허리케인 GPS 측정치가 있다고 가정해 보겠습니다. 각 GPS 측정치에는 허리케인의 이름, 위치, 기록 시간, 풍속이 기록되어 있습니다. 이러한 필드를 사용하여, 208km/h가 넘는 풍속 측정치를 가지는 Catastrophic이라는 사건을 생성할 수 있습니다. 종료 조건을 설정하지 않은 상태에서 피처가 풍속이 208 미만으로 낮아지는 시작 조건을 충족하지 않으면 사건이 종료됩니다.
다른 예시를 들면, contaminateLevel이라는 필드를 사용하여 지역 상수도의 화합물 농도를 모니터링한다고 가정해 보겠습니다. 권장 수준이 0.01mg/L 미만이고, 위험 수준이 0.03mg/L을 초과하는 경우인 것을 알고 있습니다. 값이 0.03mg/L을 초과하는 경우를 감지하고 감염 수준이 원래대로 돌아올 때까지 사건을 유지하려면, contaminateLevel > 0.03인 시작 조건과 contaminateLevel < 0.01인 종료 조건을 사용하여 사건을 생성합니다. 그러면 0.01 미만인 값이 반환될 때까지 0.03mg/L을 초과하는 값을 가진 시퀀스가 표시됩니다.
사건을 감지할 레이어 선택
사건을 찾는 데 사용할 포인트, 라인, 영역 또는 테이블입니다. 입력 레이어는 인스턴트 시간을 나타내는 피처에 대해 시간이 활성화되어 있어야 하고 추적 식별에 사용되는 필드가 하나 이상 있어야 합니다.
맵에서 레이어를 선택하는 것 이외에, 드롭다운 목록의 하단에 있는 Analysis Layer 선택을 선택하여 빅데이터 파일 공유 데이터셋 또는 피처 레이어의 콘텐츠를 찾아볼 수 있습니다.
추적을 식별할 필드를 하나 이상 선택
추적 식별자를 나타내는 필드입니다. 추적의 특정 값을 나타내는 데 하나 또는 여러 개의 필드를 사용할 수 있습니다.
예를 들어 허리케인에 대한 추적을 재생성했다면 허리케인 이름을 추적 필드로 사용할 수 있습니다.
사건 시작을 나타내는 식 조건 작성
사건을 정의하기 위해 식 빌더를 사용해 조건을 추가합니다. 지정한 조건이 true인 경우 해당 피처는 사건입니다. 종료 조건을 지정하지 않은 경우에는 시작 조건이 더 이상 true가 아닐 때 사건이 종료됩니다.
예를 들어 필드 concentration_1과 concentration_2의 합이 concentration_3보다 큰 경우 알림을 받는다고 가정해 보겠습니다. 이렇게 하려면 ($feature["concentration_1"] + $feature["concentration_2"]) > $feature["concentration_3"])의 조건을 적용합니다.
시간 경과에 따라 농도가 어떻게 바뀌었는지에 관심이 있고 현재 concentration_1이 concentration_2에 대한 두 번의 이전 측정값보다 클 때 알리려면, $feature["concentration_1"] > $track.field["concentration_2"].history(-3,-1)와 같은 식을 사용할 수 있습니다.
사건 종료를 나타내는 식 조건 작성(선택)
필요한 경우 식 빌더를 사용하여 사건의 종료를 결정하는 조건을 추가합니다. 지정한 종료 조건이 true인 경우 피처는 더 이상 사건이 아닙니다. 종료 조건을 지정하지 않은 경우에는 시작 조건이 더 이상 true가 아닐 때 사건이 종료됩니다.
예를 들어 필드 concentration_1과 concentration_2의 합이 concentration_3보다 클 때 알림을 받고 concentration_4가 concentration_1보다 작을 때 사건을 종료한다고 가정해 보겠습니다. 이렇게 하려면 ($feature["concentration_1"] + $feature["concentration_2"]) > ($join["income"] * .20)인 시작 조건과 ($feature["concentration_4"] < $feature["concentration_1"])인 종료 조건을 적용합니다.
현재 concentration_1과 네 번의 이전 측정 평균값이 첫 번째 측정값보다 클 때 사건이 종료되게 하려면, $track.field["concentration_1"].history(-5) > $track.field["concentration_1"].history(0)와 같은 식을 사용할 수 있습니다.
보기
모든 결과 메소드는 기존 피처에 필드를 추가합니다. 어느 피처를 반환할지 여부를 결정하는 두 가지 방법이 있습니다.
- 모든 피처 - 기본 설정입니다. 입력의 모든 피처가 반환됩니다.
- 사건만 - 이 방법은 사건인 피처만 반환합니다. 사건이 아닌 것으로 확인되는 피처는 반환되지 않습니다.
시간 간격으로 데이터 분석(선택)
분석을 위해 입력 피처를 세그먼트화하는 시간 간격을 사용하여 사건을 감지할지 지정합니다. 시간 간격을 사용하는 경우 사용할 시간 간격을 설정하고 필요한 경우 참조 시간을 설정해야 합니다. 참조 시간을 설정하지 않으면 1970년 1월 1일이 적용됩니다.
예를 들어 시간 경계를 1990년 1월 1일 오전 9시에 시작하는 1일로 설정하면 각 추적이 매일 오전 9시에 잘리고 해당 세그먼트 내에서 분석됩니다.
시간 간격은 분석을 위해 더 작은 추적을 신속하게 생성하므로 계산 시간을 단축하는 가장 빠른 방법입니다. 반복되는 시간 간격으로 분할하는 것이 분석에 적합한 경우 빅데이터 처리에 사용하는 것을 권장합니다.
결과 레이어 이름
생성될 레이어의 이름입니다. ArcGIS Data Store에 작성하는 경우 결과는 내 콘텐츠에 저장되고 맵에 추가됩니다. 빅데이터 파일 공유에 작성하는 경우 결과는 빅데이터 파일 공유에 저장되고 해당 매니페스트에 추가됩니다. 이러한 결과는 맵에 추가되지 않습니다. 기본 이름은 도구 이름과 입력 레이어 이름을 기반으로 합니다. 레이어가 이미 있으면 도구를 사용할 수 없습니다.
ArcGIS Data Store(관계형 또는 시공간 빅데이터 저장소)에 작성하는 경우 결과 저장: 드롭다운 상자를 사용하여 내 콘텐츠에서 결과를 저장할 폴더의 이름을 지정할 수 있습니다.