Ricostruisci Tracce
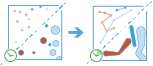
Questo strumento funziona con un layer abilitato per variazioni temporali di feature puntuali o areali che rappresentano un istante nel tempo. Innanzitutto esso determina quali feature appartengono a una traccia utilizzando un identificatore. Utilizzando il tempo in ciascuna posizione, le tracce sono ordinate in modo sequenziale e trasformate in una linea o in un'area che rappresenta la traiettoria del movimento nel tempo. Se lo si desidera, l'input può essere bufferizzato in funzione di un campo e verrà creata un'area in ciascuna posizione. Questi punti bufferizzati o le aree di input vengono uniti in modo sequenziale per creare una traccia in forma di area laddove la larghezza è indicativa dell'attributo di interesse. Le tracce generate hanno un'ora di inizio e un'ora di fine, che rappresentano temporalmente la prima e l'ultima feature in una determinata traccia. Quando si creano le tracce, vengono calcolate le statistiche su tutte le feature di input e vengono assegnate alla traccia di output. La statistica più semplice è costituita dal numero di punti compresi nell'area, tuttavia è possibile calcolare anche altre statistiche.
Le feature abilitate per variazioni temporali possono essere rappresentate in due modi diversi:
- Istante: per un singolo momento di tempo
- Intervallo: un'ora d'inizio e un'ora di fine
Si supponga, ad esempio, di avere misurazioni GPS di uragani ogni 10 minuti. Ogni misurazione GPS registra il nome dell'uragano, la posizione, l'ora di registrazione e la velocità del vento. Con queste informazioni, è possibile creare tracce per ciascun uragano utilizzando il nome per identificare la traccia. Per ogni uragano verranno generate tracce. Inoltre, è possibile calcolare statistiche come la velocità media, massima e minima del vento di ciascun uragano, nonché il numero delle misurazioni all'interno di ciascuna traccia.
Utilizzando lo stesso esempio, è possibile eseguire il buffer delle tracce in funzione della velocità del vento. Verrà eseguito il buffer di ciascuna misurazione in funzione del campo della velocità del vento in tale posizione e verranno unite le aree bufferizzate, creando un'area che rappresenta la traiettoria della traccia e le modifiche alla velocità del vento e al procedere degli uragani.
Scegliere le feature da cui ricostruire le tracce
Il layer puntuale o areale che verrà ricostruito nelle tracce. Il layer di input deve essere abilitato per le variazioni temporali con feature che rappresentano un'istante nel tempo. Il layer deve essere in un sistema di coordinate proiettate o il riferimento spaziale di elaborazione deve essere impostato su un sistema di coordinate proiettate utilizzando gli Ambienti di analisi se viene applicato un buffer.
Oltre a scegliere un layer dalla mappa, è possibile selezionare Scegli layer di analisi alla base dell'elenco a discesa per cercare un dataset di condivisione file Big Data o un feature layer.
Scegliere uno o più campi per identificare le tracce
I campi che rappresentano l'identificatore di tracce.
Ad esempio, se si stanno ricostruendo tracce di uragani, si dovrebbe usare il nome dell'uragano come campo della traccia.
Scegliere il metodo utilizzato per ricostruire le tracce
Metodo utilizzato per unire le tracce e applicare il buffer (se applicabile). Il metodo Planare consente di calcolare i risultati più velocemente ma non unisce le tracce in corrispondenza della linea di cambio data internazionale né tiene in considerazione la forma effettiva della terra durante il buffering. Il metodo Geodetico consente di unire le tracce in corrispondenza della linea di cambio data e applica un buffer geodetico tenendo in considerazione la forma effettiva della terra.
Creare un'espressione con cui eseguire il buffer di feature di input (facoltativo)
Equazione utilizzata per calcolare la distanza del buffer intorno alle feature di input. Questa equazione può essere generata utilizzando il calcolatore del buffer e operazioni di base come l'addizione, la sottrazione, la moltiplicazione e la divisione. I valori vengono calcolati utilizzando il sistema di coordinate di analisi. Il layer deve essere in un sistema di coordinate proiettate o il riferimento spaziale di elaborazione deve essere impostato su un sistema di coordinate proiettate utilizzando gli Ambienti di analisi se viene applicato un buffer.
Un'equazione come $feature.windspeed * 1000 applicherebbe un buffer di 1000 moltiplicato per il campo windspeed. È possibile utilizzare più di un campo nel calcolatore del buffer.
È inoltre possibile specificare un'espressione che prende in considerazione le tracce. Ad esempio, si supponga di calcolare la somma del valore di campo windspeed per la feature attuale e le due feature precedenti con un'equazione quale $track.field(windspeed).history(-3). In ciascuna posizione, la somma di windspeed attuale e le due misurazioni precedenti vengono calcolate e bufferizzate.
Selezionare un'ora in cui suddividere le tracce (facoltativo)
Tempo utilizzato per suddividere le tracce. Se i punti o le aree di input hanno tra loro una durata maggiore rispetto alla suddivisione del tempo, verranno suddivisi in tracce differenti.
Se si specifica una frazione di tempo e una divisione della distanza, le tracce vengono suddivise quando si soddisfa una o entrambe le condizioni.
Si supponga di avere feature puntuali che rappresentano voli di aerei, in cui il campo della traccia è l'ID dell'aereo. Questo aereo può effettuare più voli ma verrà rappresentato come una sola traccia. Sapendo che tra un volo e l'altro c'è una pausa di 1 ora, è possibile utilizzare 1 ora come suddivisione della traccia e ciascun volo verrà suddiviso nella propria traccia.
Suddividi tracce (opzionale)
È possibile suddividere le tracce usando tre metodi diversi. È possibile usare una combinazione di nessuno, tutti o alcuni dei metodi di suddivisone.
Le suddivisioni possono essere completate nei seguenti modi:
- In base alla distanza tra input: se i punti o i poligoni di input presentano tra di loro una distanza più lunga della distanza specificata, verranno suddivisi in tracce differenti. Ad esempio, se si è specificata una distanza di 10 chilometri, i punti sequenziali superiori a 10 chilometri saranno tracce separate.
- In base al tempo tra input: se i punti o i poligoni di input presentano una durata più lunga rispetto alla suddivisione temporale, verranno suddivisi in tracce differenti. Ad esempio, se si hanno feature puntuali che rappresentano voli di aerei, in cui il campo della traccia è l'ID dell'aereo. Questo aereo può effettuare più voli ma verrà rappresentato come una sola traccia. Sapendo che tra un volo e l'altro c'è una pausa di 1 ora, è possibile utilizzare
1 oracome suddivisione della traccia e ciascun volo verrà suddiviso nella propria traccia. - A intervalli di tempo definiti: suddivisione mediante intervalli regolari, specificati da un intervallo di tempo e un riferimento temporale. Se non si specifica un riferimento temporale, si userà il 1 gennaio 1970. Ad esempio, se si è specificato 1 anno con il 2 febbraio 1990 alle 10:00 come riferimento temporale, si suddivideranno le tracce in 2 febbraio 1990 alle 10:00, 2 febbraio 1991 alle 10:00 e così via a intervalli di un anno.
Se si specificano più opzioni di suddivisione, le tracce vengono suddivise quando si soddisfano una o più condizioni.
Selezionare una distanza per suddividere le tracce (facoltativo)
Distanza utilizzata per suddividere le tracce. Se i punti o le aree di input presentano una distanza più lunga della divisione della distanza, verranno suddivisi in tracce differenti.
Se si specifica una frazione di tempo e una divisione della distanza, le tracce vengono suddivise quando si soddisfa una o entrambe le condizioni.
Aggiungi statistiche (facoltativo)
È possibile calcolare le statistiche su feature riepilogate. Su campi numerici è possibile calcolare quanto segue:
- Conteggio: calcola il numero di valori nonnull. Può essere utilizzato su campi o stringhe numeriche. Il conteggio di [null, 0, 2] è 2.
- Somma: la somma dei valori numerici in un campo. La somma di [null, null, 3] è 3.
- Media: la media di valori numerici. La media di [0, 2, null] è 1.
- Min: il valore minimo di un campo numerico. Il minimo di [0, 2, null] è 0.
- Max: il valore massimo di un campo numerico. Il valore massimo di [0, 2, null] è 2.
- Intervallo: l'intervallo di un campo numerico. Questo viene calcolato come i valori minimi sottratti dal valore massimo. L'intervallo di [0, null, 1] è 1. L'intervallo di [null, 4] è 0.
- Varianza: la varianza di un campo numerico in una traccia. La varianza di [1] is null. La varianza di [null, 1,0,1,1] è 0,25.
- Deviazione standard: la deviazione standard di un campo numerico. La deviazione standard di [1] è null. La deviazione standard di [null, 1,0,1,1] è 0,5.
Su campi stringa è possibile calcolare quanto segue:
- Conteggio: il numero di stringhe nonnull.
- Qualsiasi: questa statistica è un esempio casuale di un valore stringa nel campo specificato.
Scegliere un ArcGIS Data Store in cui salvare i risultati
I risultati di GeoAnalytics sono memorizzati in un data store ed esposti come un feature layer in Portal for ArcGIS. Nella maggior parte dei casi, i risultati devono essere memorizzati nello Spatiotemporal Data Store e questa è l'impostazione predefinita. In alcuni casi,, il salvataggio dei risultati nel Data Store relazionale è un'ottima opzione. Di seguito sono memorizzate le ragioni per memorizzare i risultati nel Data Store relazionale:
- È possibile utilizzare i risultati in una collaborazione tra portali.
- È possibile abilitare funzionalità di sincronizzazione con i risultati.
Non utilizzare il Data Store relazionale se si prevede un incremento dei risultati GeoAnalytics ed è necessario sfruttare le funzionalità dello Spatiotemporal Big Data Store per gestire grandi quantità di dati.
Nome del layer dei risultati
Il nome del layer che verrà creato. Se si scrive su un ArcGIS Data Store, i risultati saranno salvati in I miei contenuti e aggiunti alla mappa. Se si scrive su una condivisione file Big Data, i risultati saranno memorizzati nella condivisione file Big Data e aggiunti al suo Manifest. Non saranno aggiunti alla mappa. Il nome predefinito è basato sul nome dello strumento e sul nome del layer di input. Se il layer esiste già, lo strumento non verrà eseguito.
Quando si scrive su ArcGIS Data Store (data store relazionale o Spatiotemporal Big Data Store) usando la casella a discesa Salva risultato in, è possibile specificare il nome di una cartella in I miei contenuti in cui salvare il risultato.