Join delle Feature
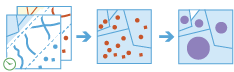
L'attività Join delle feature funziona con due layer. Join delle feature unisce gli attributi da una feature a un'altra in base a relazioni spaziali, temporali e di attributi o ad una combinazione delle tre. Questo strumento determina tutte le feature di input che soddisfano determinate condizioni di join e unisce il secondo layer di input al primo. Se lo si desidera, è possibile unire tutte le feature alle feature corrispondenti o riepilogare le feature corrispondenti.
Lo strumento Join delle feature può essere applicato a punti, linee e tabelle. Un join temporale richiede che i dati di input siano abilitati per variazioni temporali, mentre un join spaziale richiede che i dati abbiano una geometria.
Scegliere il layer di destinazione
Layer alla cui tabella verranno aggiunti gli attributi derivanti dal layer di join.
L'analisi utilizzando la relazione spaziale Vicino richiede un sistema di coordinate proiettate. È possibile impostare il Sistema di coordinate di elaborazione negli Ambienti di analisi. Se il sistema di coordinate di elaborazione non è impostato su un sistema di coordinate proiettate, verrà chiesto di impostarlo quando si Esegue l'analisi .
Oltre a scegliere un layer dalla mappa, è possibile selezionare Scegli layer di analisi alla base dell'elenco a discesa per cercare un dataset di condivisione file Big Data o un feature layer.
Scegli il layer a cui aggiungere il layer di destinazione
Layer di join con gli attributi che verrà aggiunto al layer di destinazione.
Oltre a scegliere un layer dalla mappa, è possibile selezionare Scegli layer di analisi alla base dell'elenco a discesa per cercare un dataset di condivisione file Big Data o un feature layer.
Scegli operazione Join
Determina in che modo verranno gestiti i join tra i layer di destinazione e join nell'output se più feature di join presentano la stessa relazione con il layer che deve essere unito. Esistono due operazioni di join tra cui scegliere:
- Join uno a uno: questa opzione riepiloga tutte le feature corrispondenti in ciascuna feature che deve essere unita.
- Join uno a molti: questa opzione unisce tutte le feature corrispondenti al layer di join.
Si supponga, ad esempio, di voler trovare i supermercati situati a meno di 2 km da un mercato contadino. In questo caso, il layer di destinazione ha una sola feature che rappresenta un mercato contadino, mentre il Join Layer rappresenta i negozi di alimentari locali e hanno degli attributi, come le vendite annuali totali. Utilizzando lo strumento Join delle feature, sono stati trovati cinque negozi di alimentari che soddisfano i criteri. Se si specifica l'opzione Join uno a molti, come risultato si otterranno cinque feature nel risultato e ciascuna riga rappresenta il mercato contadino e un supermercato. Se si specifica una relazione Join uno a uno, come risultato si otterranno una feature che rappresenta il mercato contadino e informazioni riepilogative dei supermercati, come il conteggio (2) e altre statistiche, ad esempio la somma delle vendite annuali.
Selezionare uno o più join
Specifica l’opzione di join utilizzata. È possibile applicare uno, due o tre tipi di join di seguito:
- Spaziale: utilizza una relazione spaziale specifica per unire le feature. Ciò richiede che entrambi i layer abbiano una geometria.
- Temporale: utilizza una relazione temporale per unire le feature. Ciò richiede che entrambi i layer siano abilitati per variazioni temporali.
- Attributo: unisce le feature in base a campi uguali.
Scegli una relazione spaziale
La relazione spaziale che determinerà se le feature sono unite tra di loro. Le seguenti relazioni disponibili dipendono dal tipo di geometria (punto, polilinea o poligono) che verrà utilizzata come feature di input:
- Interseca: le feature saranno abbinate se si intersecano tra di loro.
- Uguale a: le feature saranno abbinate se hanno la stessa geometria.
- Vicino: le feature saranno abbinate se si trovano entro una distanza specifica le une dalle altre. Il layer di destinazione deve essere in un sistema di coordinate proiettate o il riferimento spaziale di elaborazione deve essere impostato su un sistema di coordinate proiettate utilizzando gli Ambienti di analisi se si utilizza una relazione Vicino spaziale.
- Contiene: le feature saranno abbinate se il layer di destinazione è contenuto nelle feature di join.
- Interno: le feature saranno abbinate se il layer di destinazione si trova dentro le feature di join.
- Tocca: le feature saranno abbinate se hanno un confine che tocca la feature di destinazione.
- Incrocia: le feature saranno abbinate se hanno contorni che si incrociano.
- Sovrapposizioni: le feature verranno unite se si sovrappongono.
Specifica il raggio applicato a una relazione spaziale di prossimità.
Ad esempio, si supponga di avere un dataset che rappresenta un impianto nucleare e un altro che rappresenta edifici residenziali. È possibile impostare una distanza nearSpatial di 1 km per trovare le abitazioni a meno di 1 km dall'impianto nucleare.
Scegli una relazione temporale
La relazione temporale che determinerà se le feature sono unite tra di loro. Questa opzione è disponibile solo se entrambi i layer sono abilitati per variazioni temporali e le relazioni disponibili dipenderanno dal tipo di tempo (istante o intervallo) che verrà utilizzato per le feature di input. Le relazioni temporali disponibili sono le seguenti:
- Soddisfa: le feature saranno abbinate se la prima feature soddisfa la seconda.
- Soddisfatto da: le feature saranno abbinate se la prima feature è soddisfatta dalla seconda.
- Sovrapposizioni: le feature saranno abbinate se la prima feature si sovrappone alla seconda.
- Sovrapposta da: le feature saranno abbinate se la prima feature è sovrapposta dalla seconda.
- Durante: le feature saranno abbinate se la prima feature è contemporanea alla seconda.
- Contiene: le feature saranno abbinate se la prima feature contiene la seconda.
- Uguale a: le feature saranno abbinate se la prima feature è uguale alla seconda.
- Termine: le feature saranno abbinate se la prima feature termina la seconda.
- Terminata da: le feature saranno abbinate se la prima feature è terminata dalla seconda.
- Avvia: le feature saranno abbinate se la prima feature avvia la seconda.
- Avviato da: le feature saranno abbinate se la prima feature è avviata dalla seconda.
- Interseca: le feature saranno abbinate se i tempi si intersecano in ogni momento.
- Vicino: le feature saranno unite se si trovano una accanto all'altra, secondo un'ora specifica.
- Quasi prima: le feature saranno unite se la prima feature è precedente alla seconda ed entro il tempo specificato.
- Quasi dopo: le feature saranno unite se la prima feature è successiva alla seconda ed entro il tempo specificato.
Specifica il raggio temporale applicato a una relazione di prossimità temporale. Una relazione di prossimità temporale include Vicino, Quasi prima e Quasi dopo.
Ad esempio, si supponga di avere un layer di incidenti in barca e un layer di tracciati GPS per un uragano. È possibile cercare gli incidenti in barca entro una distanza specifica di tracce di uragano sia nello spazio (1 km) che nel tempo (5 ore). Come risultato si avranno gli incidenti in barca uniti agli uragani che si sono verificati in prossimità gli uni degli altri, sia nello spazio che nel tempo.
Scegli i campi da associare
Abbina i valori in un campo di un layer a quelli in un campo di un altro layer.
Ad esempio, si supponga di avere un layer geografico regionale con indirizzi di abitazioni (incluso un campo denominato ZIP) e un dataset tabulare di dati demografici relativi alla salute in base al codice postale (un campo denominato HEALTHZIP). È possibile unire il dataset relativo alla salute ai dati sugli edifici residenziali abbinando il campo ZIP al campo HEALTHZIP. Come risultato si otterrà un layer di edifici residenziali con i dati sulla salute corrispondenti.
Aggiungi statistiche (facoltativo)
Calcola le statistiche sulle feature unite se l'operazione join è Join uno a uno. Per impostazione predefinita, verranno calcolare tutte le statistiche.
È possibile calcolare le statistiche su feature riepilogate. Su campi numerici è possibile calcolare quanto segue:
- Conteggio: calcola il numero di valori nonnull. Può essere utilizzato su campi o stringhe numeriche. Il conteggio di [null, 0, 2] è 2.
- Somma: la somma dei valori numerici in un campo. La somma di [null, null, 3] è 3.
- Media: la media di valori numerici. La media di [0, 2, null] è 1.
- Min: il valore minimo di un campo numerico. Il minimo di [0, 2, null] è 0.
- Max: il valore massimo di un campo numerico. Il valore massimo di [0, 2, null] è 2.
- Intervallo: l'intervallo di un campo numerico. Questo viene calcolato come i valori minimi sottratti dal valore massimo. L'intervallo di [0, null, 1] è 1. L'intervallo di [null, 4] è 0.
- Varianza: la varianza di un campo numerico in una traccia. La varianza di [1] is null. La varianza di [null, 1,0,1,1] è 0,25.
- Deviazione standard: la deviazione standard di un campo numerico. La deviazione standard di [1] è null. La deviazione standard di [null, 1,0,1,1] è 0,5.
Su campi stringa è possibile calcolare quanto segue:
- Conteggio: il numero di stringhe nonnull.
- Qualsiasi: questa statistica è un esempio casuale di un valore stringa nel campo specificato.
Tutte le statistiche vengono calcolate su valori non null. Il layer risultante includerà un nuovo campo per ogni statistica calcolata. È possibile aggiungere un numero qualsiasi di statistiche scegliendo un attributo e una statistica.
Creare un'espressione a cui aggiungere feature (facoltativo)
Applica una condizione a determinati campi. Verranno unite solo le feature con campi che soddisfano queste condizioni.
Ad esempio, si supponga di voler applicare un join a un dataset solo per le feature in cui health_spending è maggiore del 20% di income. Applicare una condizione di join di $target["health_spending"] > ($join["income"] * .20) utilizzando il campo health_spending dal primo dataset (quello a cui vengono unite le feature) e il campo income dal secondo dataset (quello da unire).
Le condizioni di join possono essere applicate utilizzando il calcolatore di espressioni.
Scegliere il Data Store
I risultati di GeoAnalytics sono memorizzati in un data store ed esposti come un feature layer in Portal for ArcGIS. Nella maggior parte dei casi, i risultati devono essere memorizzati nello Spatiotemporal Data Store e questa è l'impostazione predefinita. In alcuni casi,, il salvataggio dei risultati nel Data Store relazionale è un'ottima opzione. Di seguito sono memorizzate le ragioni per memorizzare i risultati nel Data Store relazionale:
- È possibile utilizzare i risultati in una collaborazione tra portali.
- È possibile abilitare funzionalità di sincronizzazione con i risultati.
Non utilizzare il Data Store relazionale se si prevede un incremento dei risultati GeoAnalytics ed è necessario sfruttare le funzionalità dello Spatiotemporal Big Data Store per gestire grandi quantità di dati.
Nome del layer dei risultati
Il nome del layer che verrà creato. Se si scrive su un ArcGIS Data Store, i risultati saranno salvati in I miei contenuti e aggiunti alla mappa. Se si scrive su una condivisione file Big Data, i risultati saranno memorizzati nella condivisione file Big Data e aggiunti al suo Manifest. Non saranno aggiunti alla mappa. Il nome predefinito è basato sul nome dello strumento e sul nome del layer di input. Se il layer esiste già, lo strumento non verrà eseguito.
Quando si scrive su ArcGIS Data Store (data store relazionale o Spatiotemporal Big Data Store) usando la casella a discesa Salva risultato in, è possibile specificare il nome di una cartella in I miei contenuti in cui salvare il risultato.