Trova Hot Spot
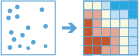
Lo strumento Trova Hot Spot consente di determinare la presenza di cluster statisticamente rilevanti nel modello spaziale dei dati.
- I punti (reati, alberi o incidenti stradali) sono realmente organizzati in cluster? Come si può verificarlo?
- È stato effettivamente individuato un hot spot di rilevanza statistica oppure la mappa raffigurerebbe una situazione diversa se venisse cambiata la simbologia?
È possibile individuare cluster anche in modelli spaziali casuali. Gli occhi e il cervello umano provano inoltre naturalmente a individuare modelli anche quando non esistono. Di conseguenza può risultare difficile sapere se i modelli presenti nei dati sono il risultato di processi spaziali reali o semplicemente il risultato del caso. È per questo motivo che ricercatori e analisti utilizzano metodi statistici, ad esempio Trova hot spot (Getis-Ord Gi*) per quantificare modelli spaziali. L'individuazione di cluster di rilevanza statistica nei dati consente di disporre di informazioni importantissime. Sapere dove e quando si verificano i cluster può offrire indizi importanti sui processi che portano alla creazione dei modelli visualizzati. Sapere, ad esempio, che il numero di furti in appartamento è particolarmente elevato in un determinato quartiere è essenziale per definire adeguate strategie di prevenzione, allocare risorse di polizia inadeguate, predisporre programmi di sorveglianza del quartiere, autorizzare investigazioni approfondite sui reati o identificare potenziali sospetti.
Scegli il layer per il quale verranno calcolati gli hot spot
Il layer di punti dal quale verranno trovati hot spot e cold spot.
Questa analisi utilizza contenitori e richiede un sistema di coordinate proiettate. È possibile impostare il Sistema di coordinate di elaborazione negli Ambienti di analisi. Se il sistema di coordinate di elaborazione non è impostato su un sistema di coordinate proiettate, verrà chiesto di impostarlo quando si Esegue l'analisi .
Oltre a scegliere un layer dalla mappa, è possibile selezionare Scegli layer di analisi alla base dell'elenco a discesa per cercare un dataset di condivisione file Big Data o un feature layer.
Trova cluster di valori alti e bassi
Questa analisi consente di rispondere alla domanda seguente: dove si raggruppano in cluster i valori alti e bassi?
Se i dati sono punti e si sceglie Conteggi punti, questo strumento valuterà la disposizione delle feature puntuali nello spazio e consentirà di rispondere alla seguente domanda: in che area i punti si raggruppano in cluster o si distribuiscono in modo imprevisto?
Se si sceglie un campo, lo strumento valuterà la disposizione nello spazio dei valori associati a ciascuna feature e consentirà di rispondere alla seguente domanda: in che area i valori alti e bassi si raggruppano in cluster?
Seleziona le dimensioni contenitore per l'aggregazione
La distanza utilizzata per generare i contenitori quadrati che verranno utilizzati per analizzare i punti di input.
Trova hot spot usando passaggi temporali (facoltativo)
Se il layer di punti è abilitato per variazioni temporali ed è di tipo istante, è possibile eseguire l'analisi utilizzando passaggi temporali.
Intervallo del passaggio temporale
Intervallo di tempo utilizzato per la generazione di passaggi temporali. Il tempo può essere allineato all'ora di inizio o all'ora di fine dei dati di input o a un periodo di riferimento specifico.
Intervallo del passaggio temporale
Intervallo di tempo utilizzato per la generazione di passaggi temporali. Il tempo può essere allineato all'ora di inizio o all'ora di fine dei dati di input o a un periodo di riferimento specifico.
Scegliere come allineare i passaggi temporali
Modalità di allineamento dei passaggi temporali. Esistono tre modi per allineare i passaggi temporali:
- Ora di inizio: i passaggi temporali sono allineati con la prima feature nel tempo.
- Ora di fine: i passaggi temporali sono allineati con l'ultima feature nel tempo.
- Ora di riferimento: i passaggi temporali sono allineati con un tempo specificato.
Ora di riferimento a cui allineare i passaggi temporale
La data e l'ora utilizzati per allineare i passaggi temporali.
Seleziona le dimensioni del confine per i calcoli hotspot
La distanza utilizzata per determinare la vicinanza utile per calcolare gli hot spot. La vicinanza deve essere maggiore delle dimensioni del contenitore per garantire che ciascun contenitore abbia almeno un vicino. Ciascun contenitore viene analizzato e confrontato con i contenitori nelle vicinanze.
Riferimento spaziale (wkid)
Questo è un parametro temporaneo per la versione provvisoria che consente di impostare il riferimento spaziale per l'elaborazione. Molti strumenti Big Data richiedono l'utilizzo di un sistema di coordinate proiettato come riferimento spaziale per l'elaborazione. Per impostazione predefinita, lo strumento utilizzerà il sistema di coordinate di input ma non verrò eseguito se si tratta di un sistema di coordinate geografiche. Per impostare un sistema di coordinate proiettato, immettere il WKID. Ad esempio, Mercatore Sferica deve essere inserito come 3857.
Scegliere un ArcGIS Data Store in cui salvare i risultati
I risultati di GeoAnalytics sono memorizzati in un data store ed esposti come un feature layer in Portal for ArcGIS. Nella maggior parte dei casi, i risultati devono essere memorizzati nello Spatiotemporal Data Store e questa è l'impostazione predefinita. In alcuni casi,, il salvataggio dei risultati nel Data Store relazionale è un'ottima opzione. Di seguito sono memorizzate le ragioni per memorizzare i risultati nel Data Store relazionale:
- È possibile utilizzare i risultati in una collaborazione tra portali.
- È possibile abilitare funzionalità di sincronizzazione con i risultati.
Non utilizzare il Data Store relazionale se si prevede un incremento dei risultati GeoAnalytics ed è necessario sfruttare le funzionalità dello Spatiotemporal Big Data Store per gestire grandi quantità di dati.
Nome del layer dei risultati
Il nome del layer che verrà creato. Se si scrive su un ArcGIS Data Store, i risultati saranno salvati in I miei contenuti e aggiunti alla mappa. Se si scrive su una condivisione file Big Data, i risultati saranno memorizzati nella condivisione file Big Data e aggiunti al suo Manifest. Non saranno aggiunti alla mappa. Il nome predefinito è basato sul nome dello strumento e sul nome del layer di input. Se il layer esiste già, lo strumento non verrà eseguito.
Nel layer risultante saranno visualizzati i cluster di rilevanza statistica con valori alti e bassi o conteggi di punti. Se il nome del layer di risultati esiste già, verrà chiesto di rinominarlo.
Quando si scrive su ArcGIS Data Store (data store relazionale o Spatiotemporal Big Data Store) usando la casella a discesa Salva risultato in, è possibile specificare il nome di una cartella in I miei contenuti in cui salvare il risultato.