Temukan Pencilan
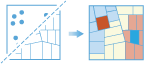
Alat Temukan Pencilan akan menentukan apakah ada pencilan yang signifikan secara statistik pada pola spasial data Anda.
- Apakah terdapat area anomali pada pola data Anda (insiden kejahatan, pohon, kecelakaan lalu lintas)? Bagaimana Anda bisa yakin?
- Apakah Anda benar-benar menemukan pencilan yang signifikan secara statistik (untuk pengeluaran, mortalitas bayi, skor tes yang tinggi secara konsisten) atau apakah peta Anda memberikan cerita yang berbeda jika Anda mengubah cara simbolisasinya?
Setiap kali kita melihat ke peta, mata dan otak kita secara alami mulai mencoba menemukan pola bahkan ketika pola tersebut tidak ada. Maka, akan menjadi sulit untuk mengetahui apakah pola pada data Anda merupakan hasil kerja nyata dari proses spasial, atau hanya merupakan hasil kemungkinan acak. Hal tersebut menjadi alasan para peneliti dan analis menggunakan metode statistik seperti Temukan Pencilan (Anselin Local Moran's I) untuk melakukan kuantifikasi pola spasial. Ketika Anda menemukan pencilan atau pengklusteran secara statistik yang signifikan pada data Anda, maka Anda memiliki informasi yang berharga. Dengan mengetahui tempat dan waktu pencilan terjadi, akan dapat memberikan petunjuk penting tentang proses yang mengakibatkan pola yang Anda lihat. Langkah selanjutnya adalah menginvestigasi penyebab hal-hal menjadi berbeda secara signifikan di area pencilan tersebut. Dengan mengetahui bahwa perampokan rumah, sebagai contoh, secara signifikan lebih tinggi pada lingkungan tertentu meskipun dikelilingi oleh lingkungan dengan tingkat perampokan yang rendah merupakan informasi penting jika Anda akan mendesain strategi pencegahan yang efektif, mengalokasikan sumber daya polisi yang terbatas, memulai program sistem keamanan lingkungan, mengotorisasi investigasi kriminal mendalam, atau mengidentifikasi tersangka potensial.
Pilih layer yang pencilannya akan dihitung
Layer titik atau area tempat pencilan akan ditemukan.
Temukan pencilan dari
Analisis ini menjawab pertanyaan: Di manakah pencilan spasial pada data saya berada?
Jika data Anda berupa titik dan Anda memilih Jumlah Titik, alat ini akan mengevaluasi pengaturan spasial fitur-fitur titik untuk menjawab pertanyaan: Di manakah titik-titik tersebut terkluster atau tersebar tidak secara semestinya?
Jika Anda memilih kolom, alat ini akan mengevaluasi pengaturan spasial dari nilai yang terkait dengan masing-masing fitur untuk menjawab pertanyaan: Di manakah nilai rendah yang dikelilingi oleh nilai tinggi? Di manakah nilai tinggi yang dikelilingi oleh nilai rendah?
Hitung titik di dalam
Defaultnya adalah menghitung titik yang berada dalam sebuah grid jaring yang dibuat oleh alat berdasarkan data titik Anda. Atau, Anda dapat memilih untuk menghitung titik dalam grid heksagon untuk menyediakan layer area (biasanya hal ini akan mencerminkan pelaporan administratif wilayah seperti sistem sensus, batas kota, atau daerah) untuk menjawab pertanyaan: Dengan mempertimbangkan jumlah titik yang dihitung pada masing-masing fitur area, apakah ada lokasi yang signifikan secara statistik dengan jumlah titik tinggi atau rendah dibandingkan dengan sekitarnya?
Tentukan tempat kemungkinan titik-titik berada
Gambar atau sediakan layer yang menentukan tempat kemungkinan terjadi insiden untuk menjawab pertanyaan: Dalam suatu area, apakah ada lokasi dengan konsentrasi titik yang tinggi atau rendah yang tidak diperkirakan?
Fitur area yang Anda gambar atau fitur pada layer area yang Anda tentukan harus menjelaskan tempat titik kemungkinan akan muncul. Untuk menggambar area ini, klik tombol Gambar dan klik lokasi pada peta untuk membuat bentuk area. Untuk menggambar area tambahan, klik kembali tombol gambar kemudian klik lokasi pada peta untuk melanjutkan.
Bagi berdasarkan
Terkadang Anda mungkin ingin menganalisis pola yang perlu dipertimbangkan yang mendasari distribusi. Contoh, jika data Anda melambangkan titik-titik kriminal, membaginya dengan total populasi akan menghasilkan analisis kejahatan per jumlah penduduk dan bukan hanya hitungan kejahatan mentah. Memilih suatu atribut untuk dibagi sering disebut sebagai normalisasi.
Memilih Populasi Esri akan memperkaya lokasi masing-masing fitur area dengan nilai populasi yang kemudian digunakan sebagai atribut untuk dibagi. Opsi ini akan menggunakan kredit.
Optimalkan untuk
Anda dapat memilih untuk mengoptimalkan kecepatan atau presisi.
Alat ini menggunakan permutasi untuk menentukan seberapa beda pola spasial data Anda dari pola acak. Meningkatkan jumlah permutasi akan meningkatkan presisi namun juga akan memperlambat waktu proses.
Opsi Override
Alat ini akan menemukan pengaturan optimal untuk Ukuran Sel dan Pita Jarak standar berdasarkan karakteristik data Anda. Namun, jika Anda memiliki Ukuran Sel tertentu atau Pita Jarak yang masuk akal untuk analisis Anda, Opsi Override dapat digunakan untuk menentukan nilai tersebut.
Opsi Override juga berguna saat menjalankan analisis pada rangkaian data yang berbeda, hal ini memungkinkan Anda untuk menyimpan Pita Jarak dan Ukuran Sel yang konsisten di antara beberapa set data. Anda kemudian dapat membandingkan hasilnya (contohnya, tingkat obesitas dan diabetes atau bahkan tingkat kejahatan pada dua tahun yang berbeda).
Ukuran Sel
Ukuran grid sel yang digunakan untuk menghitung jumlah titik di dalamnya.
Saat menggunakan grid heksagon untuk menghitung titik di dalamnya, jarak ini digunakan sebagai tinggi dari heksagon.
Pita Jarak
Masing-masing fitur dianalisis dalam konteks fitur yang berdekatan yang berlokasi pada jarak yang Anda tentukan. Alat ini akan menghitung jarak standar untuk Anda atau Anda dapat menggunakan opsi ini untuk menentukan jarak tertentu yang masuk akal untuk analisis Anda.
Contoh, jika Anda mempelajari pola komuter dan Anda tahu bahwa rata-rata perjalanan ke tempat kerja adalah 15 mil, misalnya, maka Anda dapat menggunakan pita jarak 15-mil.
Nama layer hasil
Beri nama untuk layer yang akan dibuat di Konten Saya dan tambahkan ke dalam peta. Layer hasil ini akan memperlihatkan kepada Anda pencilan yang signifikan secara statistik dengan nilai tinggi atau rendah atau jumlah titik. Jika nama layer hasil sudah ada, Anda akan diminta untuk memberi nama baru.
Dengan menggunakan kotak tarik-turun Simpan hasil, Anda dapat menentukan nama folder di Konten Saya sebagai tempat penyimpanan hasil.