Hot spotok keresése
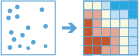
A Hot spot-ok keresése eszközzel meghatározható, hogy léteznek-e statisztikailag szignifikáns klaszterek az adatok térbeli mintázatában.
- Valóban klaszterezettek a kiválasztott pontok (bűntények, fák, közlekedési balesetek)? Hogyan tudhatja biztosan?
- Valóban statisztikailag szignifikáns hot spot-ra bukkant, vagy mást sugallna a térkép, ha megváltoztatná a megjelenítés módját?
Még a véletlenszerű térbeli minták is mutatnak bizonyos fokú klaszterezést. Ezenkívül szemünk és agyunk természetes módon mintázatokat kezd keresni, ott is, ahol nem léteznek ilyenek. Ebből adódóan nehéz megítélni, hogy az adatok mintázata valóban működő térbeli folyamatok, vagy pusztán egy véletlenszerű választás eredményei. A kutatók és elemzők ezért használják a Hot spot-ok keresése eszközhöz hasonló statisztikai módszereket (Getis-Ord Gi*) a térbeli mintázatok mennyiségi meghatározására. Az adatok között talált, statisztikailag szignifikáns klaszterek értékes információt képviselnek. A klaszterek előfordulásának helye és ideje a látható mintázatokat előidéző folyamatokkal kapcsolatos, fontos információ az elemzések során. Lényeges információ annak ismerete, hogy a lakásbetörések száma például egy adott környéken következetesen magasabb: ekkor hatékony megelőzési stratégiákat kell kidolgozni, szűkös rendőri erőforrásokat kell beosztani, lakossági figyelőszolgálatot kell megszervezni, bűncselekmények mélyreható nyomozását kell engedélyezni, vagy potenciális gyanúsítottakat kell azonosítani.
A réteg kiválasztása, amelynek hot spotjait ki szeretné számítani
A pontréteg, amelyeknek hot spot-jait és cold spot-jait („meleg” és „hideg” pontjait) az eszköz megtalálja.
Ez az elemzés gyűjtőket használ, és vetületi koordináta-rendszert igényel. A Feldolgozási koordináta-rendszert az Elemzési környezetekben állíthatja be. Ha a feldolgozási koordináta-rendszer nem vetületi koordináta-rendszerre van állítva, az eszköz ennek beállítását kéri az elemzés futtatásakor .
Ahelyett, hogy egy réteget választ a térképéről, választhatja a legördülő lista alján lévő Eredményréteg kiválasztása lehetőséget is, ha a saját tartalomban szeretne big data-fájlmegosztó adathalmazt vagy vektoros réteget keresni.
Magas és alacsony értékek klasztereinek keresése
Ez az elemzés arra a kérdésre ad választ, hogy: Hol találhatók a magas és alacsony értékek térbeli klaszterei?
Ha pont adatok esetén a Pontok száma lehetőséget választja, az eszköz a pontszerű vektor elemek térbeli elrendezésének értékelésével válaszol a kérdésre: Hol csoportosulnak nem várt módon illetve helyezkednek el szétszórtan az adatok?
Ha kiválaszt egy mezőt, az eszköz az egyes vektoros elemekhez társított értékek térbeli elrendezését értékelve válaszol a következő kérdésre: Hol találhatók magas és alacsony értékklaszterek?
Válassza ki az összevonási gyűjtőméretet
A bemenő pontok elemzésénél alkalmazott négyszög alakú gyűjtők létrehozásához használt távolság.
Hot spotok keresése időbeli lépésekkel (opcionális)
Ha az idő engedélyezve van a pontrétegen, és azonnali típusú, akkor időbeli lépéseket használva is elemezhet.
Időbeli lépés intervalluma
Az időbeli lépések létrehozásához használt időintervallum. Az idő a bemeneti adatok kezdési vagy befejezési idejéhez, vagy egy meghatározott referenciaidőhöz igazítható.
Időbeli lépés intervalluma
Az időbeli lépések létrehozásához használt időintervallum. Az idő a bemeneti adatok kezdési vagy befejezési idejéhez, vagy egy meghatározott referenciaidőhöz igazítható.
Válassza ki az időbeli lépések igazításának módját
Az időbeli lépések igazításának módja. Az időbeli lépések háromféleképpen igazíthatók:
- Kezdési idő – az időbeli lépéseket az időben első vektoros elemhez igazítja.
- Befejezési idő – az időbeli lépéseket az időben utolsó vektoros elemhez igazítja.
- Referenciaidő – az időbeli lépéseket egy meghatározott időponthoz igazítja.
Az időbeli lépések igazításához használt referenciaidő
Az időbeli lépések igazításához használt dátum és időpont.
Válassza ki a szomszédság méretét a hotspot-számításokhoz
A hotspot-számításokhoz használt szomszédság meghatározásához használt távolság. A szomszédságnak nagyobbnak kell lennie a gyűjtő méreténél, hogy mindegyik gyűjtő rendelkezzen legalább egy szomszéddal. Mindegyik gyűjtőt elemzi és összehasonlítja a szomszédos gyűjtőkkel.
SpatialReference (WKID)
Ez az előzetes kiadás egy ideiglenes paramétere az alkalmazott térbeli referencia beállításához. Számos big data eszköz vetületi koordináta-rendszer alkalmazását kívánja meg térbeli referenciaként a feldolgozáshoz. Az eszköz alapértelmezés szerint a bemeneti koordináta-rendszert használja, de eredménytelen lesz, ha az földrajzi koordináta-rendszer. Vetületi koordináta-rendszer beállításához adja meg a WKID-t. A Web Mercator esetén például 3857-et kell beírni.
ArcGIS Data Store adattár kiválasztása az eredmények mentéséhez
A geoanalitikai eredmények mentése egy adattárban történik, és a(z) Portal for ArcGIS vektoros rétegeiként szerepelnek. Az eredményeket többnyire a térbeli-időbeli adattárban ajánlott tárolni, és az alapértelmezett beállítás is ez. Egyes esetekben jó választás lehet az eredmények mentése a relációs adattárban. Az alábbi érvek szólnak az eredmények relációs adattárban történő tárolása mellett:
- Az eredmények portálok közötti együttműködésben használhatók.
- Engedélyezheti az eredményekkel való szinkronizálási lehetőségeket
Nem ajánlott a relációs adattár használata, ha a geoanalitikai eredmények mennyiségének növekedése várható, és ki kell használni a térbeli-időbeli big data-adattár képességeit a nagy adatmennyiség kezelésére.
Eredmény réteg neve
A létrehozandó réteg neve. Ha egy ArcGIS Data Store helyre ír, akkor eredményei a Saját tartalom alatt lesznek elmentve, és hozzá lesznek adva a térképhez. Ha egy big data fájlmegosztóba ír, akkor eredményei a big data fájlmegosztóba lesznek elmentve, és hozzá lesznek adva annak jegyzékfájljához. Nem lesznek hozzáadva a térképhez. Az alapértelmezett név az eszköz nevétől és a bemenő réteg nevétől függ. Ha a réteg már létezik, akkor a művelet sikertelen lesz.
Az eredmény réteg megjeleníti a magas és alacsony értékek vagy pontszámok statisztikailag szignifikáns klasztereit. Ha az eredmény réteg neve már létezik, akkor a program megkéri, hogy nevezze át.
Ha ArcGIS Data Store (relációs vagy térbeli-időbeli big data adattárba) ír az Eredmény mentési helye legördülő mező használatával, akkor megadhatja a Saját tartalom mappájának nevét, ahová az eszköz menti az eredményt.