हॉट स्पॉट खोजें
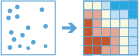
हॉट स्पॉट खोजें टूल निर्धारण करेगा यदि आपके डेटा के स्पेशियल पैटर्न में कोई भी सांख्यिकीय महत्वपूर्ण समूह है।
- क्या आपके बिंदु (अपराध घटनाएं, पेड़ या यातायात दुर्घटनाएं) वास्तव में समूहबद्ध हैं? आप इतने सुनिश्चित कैसे हो सकते हैं?
- क्या आपने सचमुच कोई उल्लेखनीय हॉट स्पॉट खोजा है, या यदि आपने इसके चिह्नित होने का तरीका बदला है तो क्या आपका मानचित्र कोई अलग कहानी बताएगा?
यहां तक कि अनियमित स्पेशियल पैटर्न कुछ हद तक समूहीकरण के प्रमाण दर्शाते हैं। इसके अलावा, हमारी आँखें और दिमाग स्वाभाविक रूप से पैटर्न खोजने के प्रयास करता है, भले ही कोई भी मौजूद ना हो। परिणामस्वरूप, यह जानना मुश्किल हो सकता है कि आपके डेटा में पैटर्न, काम पर वास्तविक स्पेशियल प्रक्रिया या अनियमित मौके के परिणाम हैं। इसीलिए शोधकर्ता और विश्लेषक स्पेशियल प्रतिमान की गणना हेतु हॉट स्पॉट खोजें (Getis-Ord Gi*) जैसे सांख्यिक तरीके इस्तेमाल करते हैं। जब आप अपने डेटा में सांख्यिकीय महत्वपूर्ण समूह मिलता हैं, तो आप के पास बहुमूल्य जानकारी होती है। यह जानना कि कब और कहाँ समूहीकरण होता है, आपके द्वारा देखे जा रहे पैटर्न को बढ़ावा देने के बारे में महत्वपूर्ण संकेत दे सकता है। यदि आप को पुलिस संसाधनों का सीमित आवंटन, पड़ोसी की निगरानी कार्यक्रम आरंभ, गहराई से आपराधिक जांच को अधिकृत, संभावित संदिग्धों की पहचान करने और प्रभावी रोकथाम रणनीति बनाने की ज़रूरत है, तो आवासीय चोरी के बारे में जानना एक अमहत्वपूर्ण जानकारी है, उदाहरण के लिए, एक विशेष पड़ोस में लगातार अधिक होती है।
हॉट स्पॉट की गणना की जाने वाली लेयर का चयन करें
बिंदु लेयर जिसमें से हॉट और कोल्ड स्पॉट्स मिलेंगे।
यह विश्लेषण पात्रों का उपयोग करता है और अनुमानित निर्देशांक प्रणाली आवश्यक है। आप विश्लेषण परिवेश में संसाधनीय निर्देशांक प्रणाली सेट कर सकते हैं। अगर आपका प्रोसेसिंग निर्देशांक सिस्टम, प्रोजेक्ट किए गए निर्देशांक सिस्टम पर सेट नहीं है, तो आपको विश्लेषण चलाते समय इसे सेट करने के लिए संकेत किया जाएगा।
अपने नक्शे से एक लेयर चुनने के अलावा, आप बड़ी डेटा फ़ाइल साझा डेटासेट या फीचर लेयर के लिए अपनी सामग्री ब्राउज़ करने के लिए ड्रॉप-डाउन सूची के निचले भाग में विश्लेषण लेयर चुनें चुन सकते हैं।
उच्च और निम्न समूहों का पता लगाएं
यह विशेलेष्ण प्रश्न का उत्तर देता है, कहां उच्च और निम्न मानों के स्पेशियल समूह हैं?
यदि आपका डेटा बिंदु हैं और आप चुनते हैं बिंदु संख्या, यह टूल प्रश्न का उत्तर देने के लिए बिंदु फीचर्स की स्पेशियल व्यवस्था का मूल्यांकन करेगा: जहां बिंदु अप्रत्याशित रूप से समूह में हैं या बिखरे हुए हैं?
यदि आप एक फील्ड का चयन करते हैं, तो यह टूल प्रश्न का उत्तर देने के लिए प्रत्येक बिंदु फीचर से संबंधित मान की स्पेशियल व्यवस्था का मूल्यांकन करेगा: उच्च और निम्न मानों के समूहीकरण है?
संकलन के लिए बिन के आकार का चयन करें
वर्गाकार डिब्बों को तैयार करने के लिए प्रयुक्त दूरी का प्रयोग आपके इनपुट बिंदुओं के विश्लेषण के लिए किया जाएगा।
समय अंतराल के उपयोग से हॉट स्पॉट खोजें (वैकल्पिक)
यदि बिंदु लेयर पर समय सक्रिय होता है, तथा यह तत्काल प्रकार का है, तो आप समय अंतरालों का प्रयोग करके विश्लेषण कर सकते हैं।
समय अंतराल
समय अंतराल पैदा करने हेतु प्रयुक्त समय का अंतराल। समय को इनपुट डेटा के शुरूआती या समापन समय के लिए, अथवा निर्दिष्ट संदर्भ समय के लिए संरेखित किया जा सकता है।
समय अंतराल
समय अंतराल पैदा करने हेतु प्रयुक्त समय का अंतराल। समय को इनपुट डेटा के शुरूआती या समापन समय के लिए, अथवा निर्दिष्ट संदर्भ समय के लिए संरेखित किया जा सकता है।
चयन करें कि समय अंतराल को कैसे संरेखित किया जाए
समय अंतराल कैसे संरेखित किए जाते हैं। समय अंतराल संरेखित करने के तीन तरीके हैं:
- समय शुरू करें—समय में प्रथम फीचर के साथ समय अंतराल संरेखित होते हैं।
- समाप्ति समय—समय में अंतिम फीचर के साथ समय अंतराल संरेखित होते हैं।
- संदर्भ समय—किसी निर्दिष्ट समय के साथ समय अंतराल संरेखित होते हैं।
में समय अंतराल संरेखित करने के लिए संदर्भ समय
समय अंतराल संरेखित करने में प्रयुक्त तारीख एवं समय।
हॉट स्पॉट की गणना के लिए पड़ोस के आकार का चयन करें
हॉट स्पॉट की गणनाओं के लिए प्रयुक्त पड़ोस को सुनिश्चित करने हेतु प्रयुक्त दूरी। प्रत्येक बिन का कम से कम एक समीपी होना सुनिश्चित करने के लिए समीपी क्षेत्र बिन के आकार से बड़ा होना चाहिए। प्रत्येक डिब्बे का विश्लेषण और तुलना पड़ोस के डिब्बों से की जाती है।
SpatialReference (wkid)
यह प्रसंस्करण स्थानिक संदर्भ सेट करने के लिए पूर्व-रिलीज़ के लिए एक अस्थायी पैरामीटर है। कई बड़े डेटा टूल के लिए एक अनुमान समन्वय प्रणाली को प्रसंस्करण के लिए स्थानिक संदर्भ के रूप में प्रयोग किए जाने की आवश्यकता होती है। डिफ़ॉल्ट रूप से, टूल इनपुट समन्वय प्रणाली का उपयोग करेगा, लेकिन अगर यह एक भौगोलिक समन्वय प्रणाली है तो असफल हो जायेगा। एक प्रक्षेपित समन्वय प्रणाली सेट करने के लिए, WKID प्रविष्ट करें। उदाहरण के लिए, वेब मर्केटर के लिए 3857प्रविष्ट किया जाएगा।
परिणाम सहेजने के लिए ArcGIS Data Store चुनें
GeoAnalytics परिणामों को डेटा स्टोर में संग्रहित किया जाता है और इसे फ़ीचर लेयर के रूप में Portal for ArcGIS पर प्रदर्शित किया जाता है। अधिकतर मामलों में, परिणाम स्थान-कालिक आंकड़ा संग्रह में संग्रहित किए जाने चाहिए और यह मौलिक है। कुछ मामलों में, रिलेशनल डेटा स्टोर पर परिणामों को सहेजना एक अच्छा विकल्प होता है। नीचे वे परिणाम दिए गए हैं जिनके लिए हो सकता है कि आप परिणामों को रिलेशनल डेटा स्टोर पर सहेजना चाहें:
- आप उपयोग पोर्टल-से-पोर्टल समन्वयन में कर सकते हैं।
- आप अपने परिणामों के साथ सिंक करने की क्षमताएं सक्षम कर सकते हैं।
अगर आपको अपने GeoAnalytics परिणामों में बढ़ोत्तरी की उम्मीद हो तो आपको रिलेशनल डेटा स्टोर का उपयोग नहीं करना चाहिए और आपको बड़ी मात्रा में डेटा को हैंडल करने की स्पाशियोटेम्पोरल बिग डेटा स्टोर की क्षमताओं का लाभ उठाना चाहिए।
परिणामी लेयर का नाम
उ स लेयर का नाम जिसे बनाया जाएगा। अगर आप ArcGIS Data Storeपर लिख रहे हैं, तो आपके परिणामों को मेरी सामग्री में सहेजा जाएगा और उन्हें मैप पर जोड़ा जाएगा। अगर आप बिग डेटा फ़ाइल शेयर पर लिख रहे हैं, तो, आपके परिणामों को बिग डेटा फ़ाइल शेयर में संग्रहित किया जाएगा और इसके मैनिफेस्ट में जोड़ा जाएगा। उसे मैप में नहीं जोड़ा जाएगा। इसका मूल नाम उपकरण के नाम और इनपुट लेयर के नाम पर आधारित है। अगर लेयर पहले से मौजूद है, तो टूल असफल हो जायेगा।
यह परिणामी लेयर आप को उच्च और निम्न मानों या बिंदु संख्या के सांख्यिकीय महत्वपूर्ण समूह दिखाएगी। यदि परिणामी लेयर का नाम पहले से ही मौजूद हैं, तो आप से यह नाम बदलने के लिए कहा जाएगा।
ArcGIS Data Store(रिलेशनल या स्पेशियोटेम्पोरल बिग डेटा स्टोर) पर इसमें परिणाम सहेजें ड्रॉप डाउन बॉक्स का उपयोग करके लिखते समय, आप मेरी सामग्री में फ़ोल्डर का नाम निर्दिष्ट कर सकते हैं, जहां परिणाम सहेजा जाएगा।