Detect Incidents
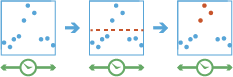
This tool works with a time-enabled layer of points, lines, areas, or tables that represents an instant in time. Using sequentially ordered features, called tracks, this tool determines which features are incidents of interest. Incidents are determined by conditions that you specify.
First, the tool determines which features belong to a track using one or more fields. Using the time at each feature, the tracks are ordered sequentially and the incident condition is applied. Features that meet the starting incident condition are marked as an incident. You can optionally apply an ending incident condition; when the end condition is true, the feature is no longer an incident. The results will be returned with the original features—with new columns representing the incident name—and indicate which feature meets the incident condition. You can return all original features or only the features that are incidents.
For example, suppose you have GPS measurements of hurricanes every 10 minutes. Each GPS measurement records the hurricane's name, location, time of recording, and wind speed. Using these fields, you could create an incident where any measurement with a wind speed greater than 208 km/h is an incident titled Catastrophic. By not setting an end condition, the incident would end if the feature no longer meets the start condition (wind speed slows down to less than 208).
Using another example, suppose you were monitoring concentrations of a chemical in your local water supply using a field called contaminateLevel. You know that the recommended levels are less than 0.01 mg/L, and dangerous levels are above 0.03 mg/L. To detect incidents where a value above 0.03mg/L is an incident and remains an incident until contamination levels are back to normal, you create an incident using a start condition of contaminateLevel > 0.03 and an end condition of contaminateLevel < 0.01. This will mark any sequence where values exceed 0.03mg/L until they return to a value less than 0.01.
Choose layer to detect incidents from
The points, lines, areas, or tables that will be used to find incidents. The input layer must be time enabled with features that represent an instant in time, as well as have one or more fields that can be used to identify tracks.
In addition to choosing a layer from your map, you can choose Choose Analysis Layer at the bottom of the drop-down list to browse to your contents for a big data file share dataset or feature layer.
Select one or more fields to identify tracks
The fields that represent the track identifier. You can use one field or multiple fields to represent unique values of tracks.
For example, if you were reconstructing tracks of hurricanes, you could use the hurricane name as the track field.
Build an expression condition to signify the start of an incident
Add a condition using the expression builder to determine what an incident is. If the condition you specify is true, the feature is an incident. If you do not specify an end condition, an incident ends when the start condition is no longer true.
For example, suppose you want to be alerted when the sum of fields concentration_1 and concentration_2 is greater than concentration_3. To do this, apply a condition of ($feature["concentration_1"] + $feature["concentration_2"]) > $feature["concentration_3"]).
If you were interested in how the concentrations changed over time, and wanted to be alerted when the current concentration_1 was greater than the two previous measurements of concentration_2 you could use an expression like $feature["concentration_1"] > $track.field["concentration_2"].history(-3,-1).
Build an expression condition to signify the end of an incident (optional)
Optionally add a condition using the expression builder to determine the end of an incident. If the end condition you specify is true, the feature is no longer an incident. If you do not specify an end condition, an incident ends when the start condition is no longer true.
For example, suppose you want to be alerted when the sum of fields concentration_1 and concentration_2 is greater than concentration_3, and you want the incident to end if concentration_4 is less than concentration_1. To do this, apply a start condition of ($feature["concentration_1"] + $feature["concentration_2"]) > ($join["income"] * .20) and an end condition of ($feature["concentration_4"] < $feature["concentration_1"]).
If you wanted an incident to end when the mean of the current concentration_1 and four previous measurements was greater than the first measurement you could use an expression like $track.field["concentration_1"].history(-5) > $track.field["concentration_1"].history(0).
Show me
All output methods will append fields to the original features. There are two ways to determine which features are returned:
- All features—This is the default. All features in the input will be returned.
- Only incidents—This method will only return the features that are incidents. Any features that are not found to be incidents will not be returned.
Analyze data with time intervals (optional)
Specify if you want to detect incidents using time intervals which segment your input features for analysis. If you use time intervals you must set the time interval you want to use, and optionally set the reference time. If you don't set a reference time, Jan 1, 1970 will be used.
For example, if you set the time boundary to be 1 day, starting at 9:00 AM on January 1st, 1990, than each track will be truncated at 9:00 am for every day and analyzed within that segment.
Using time intervals is a fast way to accelerate computing time, as it quickly creates smaller tracks for analysis. If splitting by a reoccurring time interval makes sense for your analysis, it is recommend for big data processing.
Result layer name
The name of the layer that will be created. If you are writing to an ArcGIS Data Store, your results will be saved in My Content and added to the map. If you are writing to a big data file share, your results will be stored in the big data file share and added to its manifest. It will not be added to the map. The default name is based on the tool name and the input layer name. If the layer already exists, the tool will fail.
When writing to ArcGIS Data Store (relational or spatiotemporal big data store) using the Save result in drop-down box, you can specify the name of a folder in My Content where the result will be saved.