Reconstruire les pistes
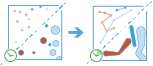
Cet outil fonctionne avec une couche temporelle d’entités ponctuelles ou surfaciques qui représentent un instant donné dans le temps. Il commence par identifier les entités qui appartiennent à une piste à l'aide d'un identifiant. En utilisant l’heure de chaque emplacement, les pistes sont classées séquentiellement et transformées en une ligne ou une surface représentant la trajectoire du déplacement au fil du temps. L’entrée peut également être bufférisée par un champ, ce qui génère une surface à chaque emplacement. Ces points bufférisés, ou les surfaces en entrée, sont ensuite joints séquentiellement pour créer une piste sous forme d’une surface dont la longueur est représentative de l’attribut qui vous intéresse. Les pistes générées possèdent une heure de début et de fin, qui représentent temporellement la première et la dernière entités dans une piste donnée. Lorsque les pistes sont créées, des statistiques concernant les entités en entrée sont calculées et attribuées à la piste en sortie. La statistique la plus élémentaire est le total de points au sein de la surface, mais vous pouvez également en calculer d'autres.
Les entités dans les couches temporelles peuvent être représentées de deux manières :
- Instant : un seul moment dans le temps
- Intervalle : une heure de début et de fin
Supposons par exemple que vous possédiez des mesures GPS d'ouragans toutes les 10 minutes. Chaque mesure GPS consigne le nom de l'ouragan, sa position, l'heure d'enregistrement et la vitesse du vent. Avec ces informations, vous pouvez créer des pistes pour chaque ouragan en utilisant le nom pour identifier la piste. Des pistes pour chaque ouragan sont alors générées. Vous pouvez en outre calculer des statistiques, telles que la vitesse moyenne, maximale et minimale du vent pour chaque ouragan, ainsi que le total de mesures au sein de chaque piste.
En utilisant le même exemple, vous pouvez buffériser vos pistes en fonction de la vitesse du vent. Cette opération a pour effet de buffériser chaque mesure en fonction du champ de vitesse du vent à cet emplacement et de joindre les surfaces bufférisées ensemble, générant une surface représentative de la trajectoire de la piste, ainsi que l’évolution de la vitesse du vent au fur et à mesure de la progression des ouragans.
Choisir les entités à partir desquelles reconstruire les pistes
Couche ponctuelle ou surfacique qui sera reconstituée en pistes. Le couche en entrée doit être temporelle avec des entités représentant un instant donné dans le temps. La couche doit se trouver dans un système de coordonnées projetées ou la référence spatiale de traitement doit être définie sur un système de coordonnées projetées à l'aide des environnements d'analyse si une zone tampon est appliquée.
Outre le fait de choisir une couche de votre carte, vous pouvez sélectionner Choose Analysis Layer (Choisir une couche d’analyse) au bas de la liste déroulante pour parcourir votre contenu et rechercher une couche d’entités ou un jeu de données de partage de fichiers Big Data.
Choisir un ou plusieurs champs pour identifier les pistes
Les champs qui représentent l'identifiant de piste.
Par exemple, si vous reconstruisez les pistes des ouragans, vous pouvez utiliser le nom de l'ouragan comme nom de piste.
Choisir la méthode utilisée pour reconstruire les pistes
Méthode utilisée pour joindre des pistes et appliquer une zone tampon (le cas échéant). La méthode planaire peut calculer les résultats plus rapidement, mais elle n'enroule pas les pistes autour de la ligne internationale de changement de date ou ne tient pas compte de la forme réelle de la Terre lors de la bufférisation. La méthode géodésique enroule les pistes autour de la ligne de changement de date le cas échéant et applique une zone tampon géodésique pour tenir compte de la forme réelle de la Terre.
Créer une expression en fonction de laquelle mettre en zone tampon les entités en entrée (facultatif)
Equation utilisée pour calculer la distance de la zone tampon autour des entités en entrée. Cette équation peut être générée à l'aide de la calculatrice de zone tampon. En outre, les opérations élémentaires, telles que l'ajout, la soustraction, la multiplication et la division sont prises en charge. Les valeurs sont calculées à l'aide du système de coordonnées d'analyse. La couche doit se trouver dans un système de coordonnées projetées ou la référence spatiale de traitement doit être définie sur un système de coordonnées projetées à l'aide des environnements d'analyse si une zone tampon est appliquée.
Une équation telle que $feature.windspeed * 1000 applique une zone tampon de 1 000 multipliée par le champ windspeed. Vous pouvez utiliser plusieurs champs dans la calculatrice de zone tampon.
Vous pouvez également spécifier une expression de suivi de gestion. Par exemple, vous pouvez calculer la somme de la valeur des champs windspeed pour l’entité actuelle et pour les deux entités précédentes avec une équation du type $track.field(windspeed).history(-3). À chaque emplacement, la somme de la mesures windspeed actuelle et des deux mesures précédentes seront calculées et bufférisées.
Sélectionner une heure en fonction de laquelle fractionner les pistes (facultatif)
Temps utilisé pour fractionner les pistes. Si les points ou surfaces en entrée sont séparés par une durée plus longue que la fraction temporelle, ils sont fractionnés en différentes pistes.
Si vous spécifiez une fraction temporelle et une distance temporelle, les pistes sont fractionnées lorsque l’une des conditions ou les deux sont établies.
Imaginez que vous possédez des entités ponctuelles représentant des vols aériens, où le champ de piste est un ID d'avion. Cet avion peut effectuer plusieurs voyages et est représenté sous la forme d'une piste unique. Si vous savez qu'une pause d'une heure sépare chaque vol, vous pouvez utiliser 1 heure comme fraction pour les pistes. Chaque vol est alors fractionné dans sa propre piste.
Fractionner les pistes (facultatif)
Vous pouvez fractionner les pistes de trois façons différentes. Vous pouvez utiliser une combinaison d’entre elles, appliquer toutes les méthodes de fractionnement ou n’en appliquer aucune.
Il est possible de procéder aux fractionnements comme suit :
- Based on a distance between inputs (Selon une distance entre les entrées) : si les points ou surfaces en entrée sont séparés par une durée plus large que la distance temporelle, ils sont fractionnés en différentes pistes. Si, par exemple, vous spécifiez une distance de 10 kilomètres, les points séquentiels situés au-delà de ces 10 kilomètres font partie de pistes différentes.
- Based on a time between inputs (Selon un temps entre les entrées) : si les points ou surfaces en entrée sont séparés par une durée plus longue que la fraction temporelle, ils sont fractionnés en différentes pistes. Par exemple, vous possédez des entités ponctuelles représentant des vols aériens pour lesquels le champ de piste est un ID d’avion. Cet avion peut effectuer plusieurs voyages et est représenté sous la forme d'une piste unique. Si vous savez qu'une pause d'une heure sépare chaque vol, vous pouvez utiliser
1 heurecomme fraction pour les pistes. Chaque vol est alors fractionné dans sa propre piste. - At defined time intervals (À intervalles temporels définis) : fractionnez selon des intervalles réguliers, spécifiés par un intervalle temporel et une date de référence. Si vous ne spécifiez pas de temps de référence, la date du 1er janvier 1970 est employée. Si, par exemple, vous spécifiez 1 an avec la date de référence du 2 février 1990 à 10 heures, vous pouvez diviser les pistes le 2 février 1990 à 10 heures, le 2 février 1991 à 10 heures et ainsi de suite tous les ans.
Si vous spécifiez plusieurs options de fractionnement, les pistes sont fractionnées lorsque l’une des conditions au moins est établie.
Sélectionner une distance en fonction de laquelle fractionner les pistes (facultatif)
Distance utilisée pour fractionner les pistes. Si les points ou surfaces en entrée sont séparés par une plus grande distance que la distance temporelle, ils sont fractionnés en différentes pistes.
Si vous spécifiez une fraction temporelle et une distance temporelle, les pistes sont fractionnées lorsque l’une des conditions ou les deux sont établies.
Ajouter des statistiques (facultatif)
Vous pouvez calculer des statistiques sur des entités synthétisées. Dans les champs numériques, vous pouvez calculer ce qui suit :
- Count (Total) : calcule le nombre de valeurs non Null. Il peut être utilisé sur des champs numériques ou des chaînes. Le total de [Null, 0, 2] est égal à 2.
- Somme : somme des valeurs numériques dans un champ. La somme de [Null, 0, 3] est égale à 3.
- Moyenne : moyenne des valeurs numériques. La moyenne de [0, 2, Null] est égale à 1.
- Min : valeur minimale d'un champ numérique. La valeur minimale de [0, 2, Null] est égale à 0.
- Max : valeur maximale d'un champ numérique. La valeur maximale de [0, 2, Null] est égale à 2.
- Plage : plage d'un champ numérique. Elle est calculée pour correspondre aux valeurs minimales soustraites de la valeur maximale. La plage de [0, Null, 1] est égale à 1. La plage de [Null, 4] est égale à 0.
- Variance : variance d'un champ numérique dans une piste. La variance de [1] est la valeur Null. La variance de [null, 1,0,1,1] est égale à 0,25.
- Ecart type : écart type d'un champ numérique. L'écart type de [1] est la valeur Null. L’écart type de [null, 1,0,1,1] est égale à 0,5.
Dans les champs de type chaîne, vous pouvez calculer ce qui suit :
- Total : le nombre de chaînes différentes de la valeur Null.
- Tout : cette statistique est un échantillon aléatoire d'une valeur de chaîne dans le champ spécifié.
Choisir une instance ArcGIS Data Store dans laquelle enregistrer les résultats
Les résultats de géoanalyse sont stockés dans un répertoire de données et s’affichent en tant que couche d’entités dans Portal for ArcGIS. Dans la plupart des cas, les résultats doivent être stockés dans le stockage des données spatio-temporelles, ce qui est le paramètre par défaut. Dans certains cas, il peut être judicieux d’enregistrer les résultats dans un data store relationnel. Voici les raisons pour lesquelles stocker les résultats dans le data store relationnel :
- Vous pouvez utiliser les résultats en mode de collaboration de portail à portail.
- Vous pouvez activer la synchronisation de vos résultats.
Vous ne devez pas utiliser le data store relationnel si vous pensez que vos résultats GeoAnalytics vont augmenter et que vous devez tirer parti des fonctionnalités du le data store Big Data spatio-temporel pour gérer les grands volumes de données.
Nom de la couche de résultat
Nom de la couche à créer. Si vous écrivez sur une instance ArcGIS Data Store, les résultats seront enregistrés dans My Content (Mon contenu) et ajoutés à la carte. Si vous écrivez sur un partage de fichiers Big Data, les résultats seront enregistrés dans le partage de fichiers Big Data et ajoutés à son manifeste. Il ne sera pas ajouté à la carte. Le nom par défaut repose sur le nom de l'outil et sur le nom de la couche en entrée. Si la couche existe déjà, l'outil échoue.
Lors de l’écriture sur ArcGIS Data Store (répertoire de données relationnelles ou spatio-temporelles) via la zone de liste déroulante Save result in (Enregistrer le résultat dans), vous pouvez spécifier le nom d’un dossier dans My Content (Mon contenu) où le résultat sera enregistré.