Trouver des points chauds
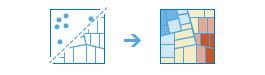
L'outil Trouver des points chauds détermine si le modèle spatial de vos données présente des agrégations statistiquement significatives.
- Vos points (délits, arbres, accidents de la circulation) sont-ils réellement agrégés ? Comment en être certain ?
- Avez-vous vraiment découvert un hot spot statistiquement significatif (dépenses, mortalité infantile, résultats d'examens élevés homogènes) ou votre carte donnerait-elle des résultats différents en modifiant sa symbolisation ?
Même les modèles spatiaux aléatoires présentent un certain degré d'agrégation. En outre, nos yeux et notre cerveau tentent naturellement d'identifier des modèles même si aucun n'existe. Par conséquent, il peut être difficile de savoir si les modèles de vos données sont le résultat de processus spatiaux réels en cours ou s'ils découlent simplement du hasard. C'est pourquoi les chercheurs et les analystes utilisent des méthodes statistiques, telles que Trouver des points chauds (Getis-Ord Gi*) pour quantifier les modèles spatiaux. La réalisation d'une agrégation statistiquement significative sur vos données permet d'obtenir des informations précieuses. Le fait de savoir où et quand l'agrégation se produit peut fournir des indications importantes sur les processus qui favorisent les modèles auxquels vous assistez. Par exemple, savoir que le nombre de cambriolages résidentiels est plus élevé dans certains quartiers constitue une information clé si vous devez mettre en place des stratégies de prévention efficaces, allouer des ressources policières limitées, initier des programmes de surveillance de quartier, autoriser des enquêtes criminelles approfondies ou identifier des suspects potentiels.
Choisissez la couche pour laquelle les points chauds seront calculés
La couche ponctuelle ou surfacique dans laquelle les points chauds et froids seront recherchés.
Rechercher des grappes de valeurs élevées et faibles
Cette analyse répond à la question suivante : où les valeurs élevées et faibles s'agrègent-elles spatialement ?
Si vos données sont des points et que vous choisissez Nombre de points, cet outil évalue l'organisation spatiale des entités ponctuelles pour répondre à la question : où trouve-t-on les points agrégés de manière inattendue ou dispersés de manière inattendue ?
Si vous choisissez un champ, cet outil évalue l'organisation spatiale des valeurs associées à chaque entité pour répondre à la question : où se trouve l'agrégation des valeurs élevées et faibles ?
Comptabiliser les points dans
Le comportement par défaut consiste à comptabiliser les points qui se trouvent dans une grille de quadrillage créée par l'outil en fonction de vos données ponctuelles. Vous pouvez également comptabiliser des points au sein d'une grille hexagonale ou indiquer une couche surfacique (qui reflète généralement des quartiers administratifs, tels que des secteurs de recensement, des limites municipales ou des comtés) pour répondre à cette question : étant donné le nombre de points comptabilisés au sein de chaque entité surfacique, est-ce qu'il existe des emplacements présentant une agrégation spatiale statistiquement significative de nombres de points élevés ou faibles ?
Définir où des points sont possibles
Dessinez ou fournissez une couche qui définit l'endroit où des incidents sont possibles pour répondre à la question suivante : au sein des zones, existe-t-il des emplacements qui présentent des concentrations de points anormalement élevées ou faibles ?
Les entités surfaciques que vous dessinez ou les entités dans la couche surfacique que vous spécifiez doivent définir l'emplacement où les points peuvent se produire. Pour dessiner ces zones, cliquez sur le bouton Dessin, puis sur un emplacement sur la carte pour créer une forme surfacique. Pour dessiner d'autres zones, cliquez à nouveau sur ce bouton, puis sur un emplacement sur la carte pour continuer.
Diviser par
Vous pouvez parfois être amené à analyser des modèles qui tiennent compte des distributions sous-jacentes. Par exemple, si vos points représentent des délits, la division par la population totale entraîne une analyse des délits par habitant et non une comptabilisation brute des délits. La normalisation consiste à identifier l'attribut en fonction duquel effectuer la division.
Si vous choisissez Population Esri, chaque entité surfacique est enrichie à l'aide des valeurs de population, qui seront ensuite utilisées comme attribut pour la division. Cette option utilise des crédits.
Options de remplacement
L'outil identifie les paramètres optimaux pour les valeurs par défaut Taille de cellule et Canal de distance en fonction des caractéristiques de vos données. Toutefois, si vous avez une valeur Taille de cellule ou Canal de distance en particulier qui est pertinente pour votre analyse, vous pouvez utiliser les options de remplacement pour définir ces valeurs.
Les options de remplacement sont également utiles lorsque vous exécutez l'analyse sur différents jeux de données. Cela permet d'assurer la cohérence des valeurs Canal de distance et Taille de cellule sur plusieurs jeux de données. Vous pouvez ensuite comparer les résultats de manière appropriée, par exemple les taux d'obésité et de diabète ou même les taux de criminalité sur deux années différentes.
Taille de cellule
Taille des cellules de grille au sein desquelles comptabiliser les points.
Lorsque vous comptabilisez les points au sein d'une grille hexagonale, cette distance sert de hauteur des polygones.
Canal de distance
Chaque entité est analysée dans le contexte de ces entités voisines se trouvant à la distance que vous spécifiez. L'outil calcule automatiquement une distance par défaut ou vous pouvez utiliser cette option pour définir une distance donnée qui est pertinente pour votre analyse.
Par exemple, si vous étudiez la migration quotidienne de travailleurs et que vous savez que le trajet moyen jusqu'au lieu de travail est de 15 km, par exemple, un canal de distance de 15 km convient pour votre analyse.
Nom de la couche résultat
Donnez un nom à la couche qui sera créée dans la page Mon contenu et ajoutée à la carte. Cette couche de résultat vous présente les grappes statistiquement significatives des valeurs élevées et faibles ou des nombres de points. Si le nom de la couche de résultats existe déjà, vous devez renommer la couche.
La zone de liste déroulante Enregistrer le résultat dans vous permet de spécifier le nom d'un dossier dans Mon contenu où le résultat sera enregistré.