Reconstruir recorridos
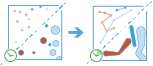
Esta herramienta trabaja con una capa con la función de tiempo habilitada de entidades de puntos o de área que representan un instante en el tiempo. Primero determina qué entidades pertenecen a un recorrido utilizando un identificador. Utilizando el tiempo en cada ubicación, los recorridos se ordenan secuencialmente y se transforman en una línea o área que representa la ruta del movimiento en el tiempo. Opcionalmente, se puede crear una zona de influencia de la entrada mediante un campo, que creará un área en cada ubicación. Estos puntos con zona de influencia o áreas de entrada se unen a continuación secuencialmente para crear un recorrido como área allí donde el ancho represente el atributo de interés. Los recorridos resultantes tendrán un tiempo de inicio y finalización, que representarán, temporalmente, la primera y la última entidad en una determinada recorrido. Cuando se crean los recorridos, se calculan estadísticas sobre las entidades de entrada y se asignan al recorrido de salida. La estadística más básica es el recuento de puntos dentro del área, pero se pueden calcular también otras estadísticas.
Las entidades en capas con la función de tiempo habilitada se pueden representar de una de estas dos formas:
- Instante: un único momento en el tiempo
- Intervalo: un tiempo de inicio y finalización
Por ejemplo, supongamos que tiene mediciones de GPS de huracanes cada 10 minutos. Cada medición de GPS registra el nombre, la ubicación, la hora de registro y la velocidad del viento del huracán. Con esta información, podría crear recorridos para cada huracán utilizando el nombre para la identificación del recorrido, y se crearían recorridos para cada huracán. Además, podría calcular estadísticas como, por ejemplo, la velocidad del viento media, máxima y mínima de cada huracán, o el recuento de mediciones dentro de cada recorrido.
Siguiendo con el mismo ejemplo, podría crear una zona de influencia de los recorridos por la velocidad del viento. De este modo se crearía una zona de influencia de cada medición por el campo de velocidad del viento en esa ubicación y se unirían las áreas con zona de influencia, así se crearía un área que representaría la ruta del recorrido, así como los cambios en la velocidad del viento a medida que evolucionan los huracanes.
Elija las entidades de las que reconstruir recorrido
La capa de puntos o área que se reconstruirá en recorridos. La capa de entrada debe ser una capa con tiempo habilitado que represente un instante en el tiempo. La capa debe estar en un sistema de coordenadas proyectado o la referencia espacial de procesamiento debe estar definida en un sistema de coordenadas proyectado mediante Entornos de análisis si se aplica una zona de influencia.
Además de elegir una capa en el mapa, puede elegir Elegir capa de análisis en la parte inferior de la lista desplegable para examinar el contenido del dataset o la capa de entidades de un recurso compartido de archivos de big data.
Elegir uno o varios campos para identificar recorridos
Los campos que representan el identificador del recorrido.
A modo de ejemplo, si estuviera reconstruyendo recorridos de huracanes, podría utilizar el nombre del huracán como el campo del recorrido.
Elegir el método utilizado para reconstruir los recorridos
Método utilizado para unir recorridos y aplicar la zona de influencia (si procede). El método Planar permite calcular los resultados más rápidamente, pero no ajustará los recorridos alrededor de la línea internacional de cambio de fecha o no representará la forma real de la Tierra a la hora de crear la zona de influencia. El método Geodésico ajustará los recorridos alrededor de la línea de cambio de fecha en caso necesario y aplicará una zona de influencia geodésica para representar la forma de la Tierra.
Cree una expresión con la que crear zonas de influencia de entidades de entrada (opcional)
Ecuación utilizada para calcular la distancia de zona de influencia alrededor de entidades de entrada. Esta ecuación se puede generar utilizando la calculadora de zonas de influencia y también se admiten operaciones básicas como, por ejemplo, sumar, restar, multiplicar y dividir. Los valores se calculan utilizando el sistema de coordenadas de análisis. La capa debe estar en un sistema de coordenadas proyectado o la referencia espacial de procesamiento debe estar definida en un sistema de coordenadas proyectado mediante Entornos de análisis si se aplica una zona de influencia.
Una ecuación del tipo $feature.windspeed * 1000 aplicaría una zona de influencia de 1.000 multiplicada por el campo windspeed. Puede utilizar más de un campo en la calculadora de zonas de influencia.
También puede especificar una expresión que realice seguimiento. Por ejemplo, podría calcular la suma el valor de campo windspeed para la entidad actual y las dos entidades anteriores con una ecuación como, por ejemplo, $track.field(windspeed).history(-3). En cada ubicación, se calcularía la suma del valor actual de windspeed y de las dos mediciones anteriores y se le aplicaría una zona de influencia.
Seleccionar un intervalo de tiempo para dividir los recorridos (opcional)
Tiempo utilizado para dividir recorridos. Si los puntos o áreas de entrada tienen una duración superior entre ellos a la división del tiempo, se dividirán en diferentes recorridos.
Si especifica una división de tiempo y otra de distancia, los recorridos se dividirán cuando se cumplan una o ambas condiciones.
Supongamos que tiene entidades de puntos que representan vuelos de aeronaves donde el campo de recorrido es el Id. de la aeronave. Esta aeronave podría realizar varios viajes y se representaría como un recorrido. Si supiera que existe un descanso de 1 hora entre los vuelos, podría utilizar 1 hora como valor para la división del recorrido y cada vuelo se dividiría entre su propio recorrido.
Dividir recorridos (opcional)
Puede dividir recorridos con tres métodos distintos. Puede no usar ningún método de división, o bien utilizar todos o algunos de ellos.
Las divisiones se pueden completar de las siguientes maneras:
- En función de la distancia entre entradas: si los puntos o áreas de entrada tienen una distancia entre ellos más amplia que la distancia especificada, se dividirán en diferentes recorridos. Por ejemplo, si especificó una distancia de 10 kilómetros, los puntos secuenciales mayores que 10 kilómetros serían recorridos separados.
- En función del tiempo entre entradas: si los puntos o áreas de entrada tienen una duración superior entre ellos a la división del tiempo, se dividirán en diferentes recorridos. Por ejemplo, si tuviera entidades de puntos que representan vuelos de aeronaves, donde el campo de recorrido es el Id. de la aeronave, esta aeronave podría realizar varios viajes y se representaría como un recorrido. Si supiera que existe un descanso de 1 hora entre los vuelos, podría utilizar
1 horacomo valor para la división del recorrido y cada vuelo se dividiría entre su propio recorrido. - A intervalos de tiempo definidos: se divide utilizando intervalos regulares, especificados por un intervalo de tiempo y un tiempo de referencia. Si no especifica ningún tiempo de referencia, se utilizará el 1 de enero de 1970. Por ejemplo, si especificó 1 año con el 2 de febrero de 1990 a las 10:00 como tiempo de referencia, dividiría los recorridos el 2 de febrero de 1990 a las 10:00, el 2 de febrero de 1991 a las 10:00, y así sucesivamente en intervalos de un año.
Si especifica varias opciones de división, los recorridos se dividirán cuando se cumplan una o varias condiciones.
Seleccionar una distancia entre la que dividir los recorridos (opcional)
Distancia utilizada para dividir recorridos. Si los puntos o áreas de entrada tienen una distancia entre ellos más amplia que la división de la distancia, se dividirán en diferentes recorridos.
Si especifica una división de tiempo y otra de distancia, los recorridos se dividirán cuando se cumplan una o ambas condiciones.
Agregar estadísticas (opcional)
Puede calcular estadísticas sobre las entidades resumidas. Puede calcular lo siguiente en los campos numéricos:
- Recuento: calcula el número de valores no nulos. Se puede usar en campos numéricos o cadenas de caracteres. El recuento de [nulo, 0, 2] es 2.
- Suma: la suma de valores numéricos en un campo. La suma de [nulo, nulo, 3] es 3.
- Media: la media de valores numéricos. La media de [0, 2, nulo] es 1.
- Mín: el valor mínimo de un campo numérico. El mínimo de [0, 2, nulo] es 0.
- Máx: el valor máximo de un campo numérico. El máximo de [0, 2, nulo] es 2.
- Rango: el rango de un campo numérico. Se calcula como los valores mínimos restados del valor máximo. El rango de [0, nulo, 1] es 1. El rango de [nulo, 4] es 0.
- Varianza: la varianza de un campo numérico en un recorrido. La varianza de [1] es nulo. La varianza de [nulo, 1,0,1,1] es 0,25.
- Desviación estándar: la desviación estándar de un campo numérico. La desviación estándar de [1] es nulo. La desviación estándar de [nulo, 1,0,1,1] es 0,5.
Puede calcular lo siguiente en los campos de cadena de caracteres:
- Recuento: el número de cadenas de caracteres no nulas.
- Cualquiera: esta estadística es una muestra aleatoria del valor de una cadena de caracteres en el campo especificado.
Seleccionar un ArcGIS Data Store en el que guardar los resultados
Los resultados de GeoAnalytics se almacenan en un data store y se exponen como capa de entidades en Portal for ArcGIS. En la mayoría de los casos, conviene almacenar los resultados en el almacén de datos espaciotemporal y este es el predeterminado. En algunos casos, guardar los resultados en el data store relacional es una buena opción. A continuación, se exponen motivos por los que guardar los resultados en el data store relacional es una buena idea:
- Puede usar los resultados en una colaboración de portal a portal.
- Puede habilitar capacidades de sincronización con sus resultados.
Conviene no usar el data store relacional si espera que los resultados de GeoAnalytics aumenten y necesita aprovechar las capacidades del big data store espaciotemporal para manejar grandes cantidades de datos.
Nombre de capa de resultados
El nombre de la capa que se creará. Si escribe en un ArcGIS Data Store, sus resultados se guardarán en Mi contenido y se agregarán al mapa. Si escribe en un recurso compartido de archivos de big data, sus resultados se almacenarán en el recurso compartido de archivos de big data y se agregarán a su manifiesto. No se agregarán al mapa. El nombre predeterminado se basa en el nombre de la herramienta y en el nombre de la capa de entrada. Si la capa ya existe, la herramienta fallará.
Cuando escriba en ArcGIS Data Store (big data store espaciotemporal o relacional) con el cuadro desplegable Guardar el resultado en, puede especificar el nombre de una carpeta de Mi contenido en la que se guardará el resultado.