Buscar valores atípicos
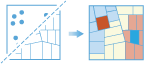
La herramienta Buscar valores atípicos determinará si hay valores atípicos estadísticamente significativos en el patrón espacial de sus datos.
- ¿Existen áreas anómalas en el patrón de sus datos (incidentes delictivos, árboles, accidentes de tráfico)? ¿Cómo puede estar seguro?
- ¿Ha descubierto de verdad un valor atípico estadísticamente significativo (para el gasto, la mortalidad infantil, notas de examen sistemáticamente altas) o contaría su mapa una historia diferente si cambiara sus símbolos?
Cada vez que miramos un mapa, nuestros ojos y cerebros empiezan a buscar instintivamente patrones aunque no exista ninguno. En consecuencia, puede ser difícil saber si los patrones de los datos son el resultado de procesos espaciales reales en acción o de una simple casualidad aleatoria. Esta es la razón por la que los investigadores y analistas utilizan métodos estadísticos como Buscar valores atípicos (I Anselin local de Moran) para cuantificar los patrones espaciales. Cuando encuentra valores atípicos estadísticamente significativos o clustering en los datos, dispone de una información valiosa. Saber dónde y cuándo se producen los valores atípicos puede proporcionar pistas importantes sobre los procesos que producen los patrones que se están viendo. El paso siguiente sería investigar por qué las cosas son significativamente diferentes en esas áreas de valores atípicos. Saber que los robos residenciales, por ejemplo, son significativamente superiores en una determinada vecindad a pesar de estar rodeada por vecindades en las que hay menos robos, es una información vital si se tienen que diseñar estrategias de prevención eficaces, asignar recursos policiales limitados, iniciar programas de vigilancia vecinal, autorizar investigaciones criminales en profundidad o identificar sospechosos potenciales.
Elija la capa cuyos valores atípicos se van a calcular
La capa de puntos o de áreas donde se buscarán valores atípicos.
Buscar valores atípicos de
Este análisis responde a la pregunta: ¿Dónde hay valores atípicos espaciales en mis datos?
Si tus datos son puntos y eliges Recuento de puntos, esta herramienta evaluará la distribución espacial de las entidades de puntos para responder a la pregunta: ¿Dónde se agrupan o se dispersan inesperadamente los puntos?
Si elige un campo, esta herramienta evaluará la distribución espacial de los valores asociados con cada entidad para responder a las preguntas: ¿Dónde hay valores bajos rodeados de valores altos? ¿Dónde hay valores altos rodeados de valores bajos?
Recuentos de puntos
El ajuste predeterminado es contar puntos dentro de una malla creada por la herramienta a partir de los datos de puntos. Si lo prefiere, puede optar por contar los puntos que hay en una cuadrícula hexagonal o por proporcionar una capa de áreas (normalmente se reflejarán los distritos de informes administrativos, tales como distritos censales, límites municipales o condados) para responder a la pregunta: Dado el número de puntos contados dentro de cada entidad de área, ¿existen ubicaciones con recuentos estadísticamente significativos de puntos altos o bajos en comparación con sus vecinos?
Definir ubicación posible de puntos
Dibuje o proporcione una capa que defina dónde se pueden dar los incidentes para responder a la pregunta: Dentro de las áreas, ¿hay alguna ubicación con concentraciones de puntos inesperadamente altas o bajas?
Las entidades de área que se dibujan o las entidades de la capa de área especificada deben definir dónde se pueden encontrar los puntos. Para dibujar estas áreas, haga clic en el botón Dibujar y, a continuación, haga clic en una ubicación del mapa para crear la forma de un área. Para dibujar otras áreas, haga clic de nuevo en el botón Dibujar y, a continuación, haga clic en una ubicación del mapa y continúe.
Dividido por
En ocasiones, se desea analizar patrones que tienen en cuenta las distribuciones subyacentes. Por ejemplo, si los puntos representan crímenes, al dividir por la población total se obtendrá un análisis de los crímenes per cápita y no un recuento de crímenes. La elección de un atributo para dividir por él se denomina en muchos casos normalización.
Al elegir Esri Population, se enriquecerá cada entidad de área con valores de población que después se usarán como atributo por el que se va a dividir. Esta opción usará créditos.
Optimizar para
Puede optar por optimizar la velocidad o la precisión.
Esta herramienta utiliza permutaciones para determinar qué grado de diferencia tiene el patrón espacial de sus datos respecto a los datos aleatorios. Al aumentar la cantidad de permutaciones aumenta la precisión, pero también el tiempo de procesamiento.
Opciones de invalidación
La herramienta buscará la configuración óptima para las opciones predeterminadas Tamaño de celda y Banda de distancia según las características de los datos. No obstante, si tiene un determinado Tamaño de celda o Banda de distancia que tiene sentido para su análisis, se pueden utilizar las Opciones de invalidación para definir esos valores.
Las Opciones de invalidación también son útiles para ejecutar análisis en distintos datasets, porque le permiten mantener la Banda de distancia y el Tamaño de celda coherentes en varios datasets. Después podrá comparar los resultados (por ejemplo, los índices de obesidad y diabetes o incluso las tasas delictivas de dos años diferentes).
Tamaño de Celda
El tamaño de las celdas de cuadrícula utilizado para contar los puntos dentro.
Cuando se utiliza una cuadrícula hexagonal para contar los puntos dentro, se utiliza la distancia como altura de los hexágonos.
Banda de distancia
Cada entidad se analiza dentro del contexto de las entidades vecinas ubicadas dentro de la distancia especificada. La herramienta calculará una distancia predeterminada o puede utilizar esta opción para definir una distancia concreta que tenga sentido para su análisis.
Por ejemplo, si está estudiando patrones de desplazamientos al trabajo y sabe que la distancia media al trabajo es de 15 millas, quizás desee utilizar una banda de distancia de 15 millas.
Nombre de capa de resultados
Proporciona un nombre para la capa que se creará en Mi contenido y se agregará al mapa. Esta capa de resultados le mostrará los valores atípicos estadísticamente significativos de valores o recuentos de puntos altos y bajos. Si el nombre de la capa de resultados ya existe, se le pedirá que le cambie el nombre.
En el cuadro desplegable Guardar el resultado en, puedes especificar el nombre de una carpeta de Mi contenido en la que se guardará el resultado.