Crear zonas de influencia
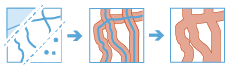
Una zona de influencia es un área que cubre una distancia dada desde una entidad de puntos, de línea o de área.
Las zonas de influencia se suelen utilizar para crear áreas que se pueden analizar más a fondo usando otras herramientas. Por ejemplo, si la pregunta es ¿Qué edificios están a 1 kilómetro del colegio?, la respuesta se puede encontrar creando una zona de influencia de 1 kilómetro en torno al colegio y superponiendo la zona de influencia con la capa que contiene las superficies de los edificios. El resultado final es una capa con los edificios que se encuentran a menos de 1 kilómetro del colegio.
Elegir una capa a la que aplicar la zona de influencia
Las entidades de puntos, líneas o áreas que se deben incluir en la zona de influencia. Las capas de entrada deben estar en un sistema de coordenadas proyectado o la referencia espacial de procesamiento debe estar definida en un sistema de coordenadas proyectado mediante Entornos de análisis.
Además de elegir una capa en el mapa, puede elegir Elegir capa de análisis en la parte inferior de la lista desplegable para examinar el contenido del dataset o la capa de entidades de un recurso compartido de archivos de big data.
Seleccionar el tipo de zona de influencia que se va a aplicar
Existen tres formas de especificar el tamaño de la zona de influencia para las entidades de entrada:
- Especificar una distancia aplicable a todas las entidades.
- Especificar un campo de la capa de entrada que contenga el valor de distancia. Puede utilizar un campo de cadena de caracteres o un campo numérico. Si no se ha definido una unidad lineal, se utilizarán las unidades de la referencia espacial. Si va a utilizar un sistema de coordenadas geográficas, se asumirá que el campo sin unidades está expresado en metros.
- Crear una expresión con varios campos y operadores matemáticos. Por ejemplo, para crear una zona de influencia 10 veces el valor de un campo denominado wind_speed, agregue la expresión $feature["wind_speed"] x 10.
Seleccionar el método de zona de influencia
Puede optar por utilizar un método Planar o un método Geodésico. El método Planar puede ser más rápido y es apropiado para análisis locales sobre datos proyectados. El método Geodésico es apropiado para áreas grandes y para cualquier sistema de coordenadas geográficas.
Seleccionar el tipo de método de disolución
Opciones para especificar el método de disolver. Si ha elegido un método de disolver, tendrá la opción de crear áreas multiparte o de una sola parte y podrá calcular estadísticas basándose en los campos proporcionados.
- Todo: se disolverán todas las entidades. Si se permiten entidades multiparte, todas las entidades se disolverán en una única entidad. Si no se permiten entidades multiparte, se disolverán las entidades adyacentes o superpuestas.
- Campos: se disolverán las entidades que compartan el mismo campo o combinación de campos que se haya especificado. Si se permiten entidades multiparte, todas las entidades con el mismo campo se disolverán en una única entidad. Si no se permiten entidades multiparte, se disolverán las entidades adyacentes o superpuestas con el mismo valor de campo.
- Nada: no se disolverá ninguna entidad. Esta es la opción predeterminada.
Permitir entidades multiparte
Opción que permite especificar si el resultado estará compuesto por entidades multiparte o de una sola parte.
- Activado: en los resultados del análisis se incluirán entidades multiparte.
- Desactivado: en los resultados del análisis se incluirán entidades de una sola parte. Es la opción predeterminada.
Agregar estadísticas (opcional)
Puede calcular estadísticas sobre las entidades resumidas. Puede calcular lo siguiente en los campos numéricos:
- Recuento: calcula el número de valores no nulos. Se puede usar en campos numéricos o cadenas de caracteres. El recuento de [nulo, 0, 2] es 2.
- Suma: la suma de valores numéricos en un campo. La suma de [nulo, nulo, 3] es 3.
- Media: la media de valores numéricos. La media de [0, 2, nulo] es 1.
- Mín: el valor mínimo de un campo numérico. El mínimo de [0, 2, nulo] es 0.
- Máx: el valor máximo de un campo numérico. El máximo de [0, 2, nulo] es 2.
- Rango: el rango de un campo numérico. Se calcula como los valores mínimos restados del valor máximo. El rango de [0, nulo, 1] es 1. El rango de [nulo, 4] es 0.
- Varianza: la varianza de un campo numérico en un recorrido. La varianza de [1] es nulo. La varianza de [nulo, 1,0,1,1] es 0,25.
- Desviación estándar: la desviación estándar de un campo numérico. La desviación estándar de [1] es nulo. La desviación estándar de [nulo, 1,0,1,1] es 0,5.
Puede calcular lo siguiente en los campos de cadena de caracteres:
- Recuento: el número de cadenas de caracteres no nulas.
- Cualquiera: esta estadística es una muestra aleatoria del valor de una cadena de caracteres en el campo especificado.
Seleccionar un ArcGIS Data Store en el que guardar los resultados
Los resultados de GeoAnalytics se almacenan en un data store y se exponen como capa de entidades en Portal for ArcGIS. En la mayoría de los casos, conviene almacenar los resultados en el almacén de datos espaciotemporal y este es el predeterminado. En algunos casos, guardar los resultados en el data store relacional es una buena opción. A continuación, se exponen motivos por los que guardar los resultados en el data store relacional es una buena idea:
- Puede usar los resultados en una colaboración de portal a portal.
- Puede habilitar capacidades de sincronización con sus resultados.
Conviene no usar el data store relacional si espera que los resultados de GeoAnalytics aumenten y necesita aprovechar las capacidades del big data store espaciotemporal para manejar grandes cantidades de datos.
Nombre de capa de resultados
El nombre de la capa que se creará. Si escribe en un ArcGIS Data Store, sus resultados se guardarán en Mi contenido y se agregarán al mapa. Si escribe en un recurso compartido de archivos de big data, sus resultados se almacenarán en el recurso compartido de archivos de big data y se agregarán a su manifiesto. No se agregarán al mapa. El nombre predeterminado se basa en el nombre de la herramienta y en el nombre de la capa de entrada. Si la capa ya existe, la herramienta fallará.
Cuando escriba en ArcGIS Data Store (big data store espaciotemporal o relacional) con el cuadro desplegable Guardar el resultado en, puede especificar el nombre de una carpeta de Mi contenido en la que se guardará el resultado.