Spuren rekonstruieren
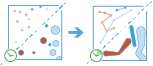
Dieses Werkzeug kann mit einem Layer mit aktivierten Zeiteigenschaften mit Punkt- oder Flächen-Features, die einen Zeitpunkt darstellen, verwendet werden. Zunächst wird anhand eines Identifikators ermittelt, welche Features zu einer Spur gehören. Mithilfe der Zeit für jede Position werden die Spuren sequenziell angeordnet und in eine Linie oder Fläche umgewandelt, die die Zugbahn im Zeitverlauf darstellt. Die Eingabe kann optional durch ein Feld gepuffert werden, wodurch an jeder Position eine Fläche erstellt wird. Diese gepufferten Punkte oder Eingabeflächen werden dann sequenziell verbunden, um eine Spur als Fläche zu erstellen, wobei die Breite das Interessenattribut darstellt. Die resultierenden Spuren haben einen Start- und einen Endpunkt, die zeitlich das erste und letzte Feature in einer angegebenen Spur darstellen. Beim Erstellen der Spuren werden Statistiken zu den Eingabe-Features berechnet und der Ausgabe-Spur zugewiesen. Die einfachste Statistik ist die Anzahl der Punkte innerhalb der Fläche. Sie können jedoch auch andere Statistiken berechnen.
Es gibt zwei Möglichkeiten, Features in Layern mit aktivierten Zeiteigenschaften darzustellen:
- Zeitpunkt: Ein einzelner Zeitpunkt
- Intervall: Eine Start- und eine Endzeit
Angenommen, Ihnen liegen alle 10 Minuten GPS-Messungen von Hurrikanen vor. Jede GPS-Messung erfasst den Namen, die Position, die Uhrzeit der Erfassung und die Windgeschwindigkeit. Mit diesen Informationen können Sie Spuren für jeden Hurrikan anhand des Namens für die Spur-ID erstellen, sodass für jeden Hurrikan Spuren erstellt werden. Außerdem können Sie Statistiken wie den Mittelwert, die maximale und minimale Windgeschwindigkeit jedes Hurrikans sowie die Anzahl der Messungen in jeder Spur berechnen.
Anhand desselben Beispiels können Sie Ihre Spuren durch die Windgeschwindigkeit puffern. Dabei werden die einzelnen Messungen durch das Windgeschwindigkeitsfeld an dieser Position gepuffert und die gepufferten Flächen verbunden. So wird eine Fläche erstellt, die den Spurpfad und die Änderungen der Windgeschwindigkeit im Verlauf von Hurrikanen darstellt.
Features zum Rekonstruieren von Spuren auswählen
Der Punkt- oder Flächen-Layer, der in Spuren rekonstruiert wird. Für den Eingabe-Layer müssen Zeiteigenschaften aktiviert sein, die einen Zeitpunkt darstellen. Der Layer muss sich in einem projizierten Koordinatensystem befinden, oder der Raumbezug für die Verarbeitung muss unter Analyseumgebungen auf ein projiziertes Koordinatensystem festgelegt werden, wenn ein Puffer angewendet wird.
Sie können nicht nur einen Layer aus der Karte auswählen, sondern auch unten in der Dropdown-Liste die Option Analyse-Layer auswählen auswählen, um zu Ihren Inhalten für ein Big-Data-Dateifreigabe-Dataset bzw. -Feature-Layer zu navigieren.
Mindestens ein Feld zum Identifizieren von Spuren auswählen
Die Felder, die die Spur-ID darstellen.
Wenn Sie beispielsweise die Spuren von Hurrikanen rekonstruieren, können Sie den Namen des Hurrikans als Spurfeld verwenden.
Methoden zum Rekonstruieren von Spuren auswählen
Die Methode, die zum Verbinden von Spuren und zum Anwenden von Puffern (falls zutreffend) verwendet wird. Die Methode Planar kann die Ergebnisse schneller berechnen, beim Puffern werden jedoch keine Spuren an der internationalen Datumslinie umgebrochen bzw. die tatsächliche Form der Erde wird nicht berücksichtigt. Bei der Methode Geodätisch werden Spuren bei Bedarf an der internationalen Datumslinie umgebrochen und wird ein geodätischer Puffer angewendet, um die Form der Erde zu berücksichtigen.
Einen Ausdruck zum Puffern von Eingabe-Features auswählen (optional)
Die Gleichung zum Berechnen der Pufferentfernung um Eingabe-Features. Diese Gleichung kann mittels Pufferberechnung erstellt werden, und grundlegende Operationen wie Addieren, Subtrahieren, Multiplizieren und Dividieren werden unterstützt. Werte werden anhand des Analyse-Koordinatensystems berechnet. Der Layer muss sich in einem projizierten Koordinatensystem befinden, oder der Raumbezug für die Verarbeitung muss unter Analyseumgebungen auf ein projiziertes Koordinatensystem festgelegt werden, wenn ein Puffer angewendet wird.
Eine Gleichung wie $feature.windspeed * 1000 wendet einen Puffer von 1.000, multipliziert mit dem Feld windspeed, an. Sie können mehrere Felder in der Pufferberechnung verwenden.
Darüber hinaus können Sie einen Tracking-bezogenen Ausdruck angeben. Beispielsweise können Sie die Summe des Feldwertes windspeed für das aktuelle Feature und die zwei vorherigen Features mit einer Gleichung wie der folgenden berechnen: $track.field(windspeed).history(-3). An jeder Position wird die Summe des aktuellen Wertes von windspeed und der zwei vorherigen Messwerte berechnet und gepuffert.
Einen Zeitraum zum Aufteilen von Spuren auswählen (optional)
Zeit, die zum Aufteilen von Spuren verwendet wird. Wenn der Zeitraum zwischen Eingabepunkten oder -flächen größer ist als die Zeitaufteilung, werden sie in verschiedene Spuren aufgeteilt.
Wenn Sie eine Zeitaufteilung und eine Entfernungsaufteilung angeben, werden Spuren aufgeteilt, wenn mindestens eine der beiden Bedingungen erfüllt ist.
Angenommen, Sie verfügen über Punkt-Features, die Flugzeuge darstellen, und das Spurfeld entspricht der Flugzeug-ID. Dieses Flugzeug kann mehrere Flüge durchführen und wird als eine Spur dargestellt. Wenn Ihnen bekannt ist, dass zwischen den Flügen eine einstündige Pause liegt, können Sie 1 Stunde als Spuraufteilung verwenden und jeder Flug wird in eine eigene Spur unterteilt.
Spuren aufteilen (optional)
Spuren lassen sich mit drei verschiedenen Methoden teilen. Sie können eine Kombination aus keiner, allen oder einigen der Teilungsmethoden verwenden.
Teilungen können auf folgende Arten durchgeführt werden:
- Basierend auf einer Entfernung zwischen Eingaben: Wenn die Entfernung zwischen Eingabepunkten oder -flächen größer ist als die angegebene Entfernung, werden sie in verschiedene Spuren aufgeteilt. Wenn Sie zum Beispiel eine Entfernung von 10 Kilometern festgelegt haben, werden nachfolgende Punkte, die mehr als 10 Kilometer entfernt sind, zu getrennten Spuren.
- Basierend auf einer Zeit zwischen Eingaben: Wenn der Zeitraum zwischen Eingabepunkten oder -flächen größer ist als die Zeitaufteilung, werden sie in verschiedene Spuren aufgeteilt. Beispiel: Sie verfügen über Punkt-Features, die Flugzeuge darstellen, und das Spurfeld entspricht der Flugzeug-ID. Dieses Flugzeug kann mehrere Flüge durchführen und wird als eine Spur dargestellt. Wenn Ihnen bekannt ist, dass zwischen den Flügen eine einstündige Pause liegt, können Sie
1 Stundeals Spuraufteilung verwenden und jeder Flug wird in eine eigene Spur unterteilt. - In definierten Zeitintervallen: Die Teilung erfolgt anhand regelmäßiger Intervalle, die durch ein Zeitintervall und eine Referenzzeit festgelegt sind. Wird keine Bezugszeit festgelegt, wird der 1. Januar 1970 verwendet. Wenn Sie beispielsweise 1 Jahr mit der Bezugszeit 2. Februar 1990 um 10:00 Uhr angegeben haben, werden Spuren am 2. Februar 1990 um 10:00 Uhr, am 2. Februar 1991 um 10:00 Uhr usw. aufgeteilt, und dieser Vorgang wird in Intervallen von einem Jahr fortgesetzt.
Wenn Sie mehrere Teilungsoptionen festlegen, werden Spuren aufgeteilt, wenn eine oder mehrere Bedingungen erfüllt sind.
Eine Entfernung zum Aufteilen von Spuren auswählen (optional)
Entfernung, die zum Aufteilen von Spuren verwendet wird. Wenn die Entfernung zwischen Eingabepunkten oder -flächen größer ist als die Entfernungsaufteilung, werden sie in verschiedene Spuren aufgeteilt.
Wenn Sie eine Zeitaufteilung und eine Entfernungsaufteilung angeben, werden Spuren aufgeteilt, wenn mindestens eine der beiden Bedingungen erfüllt ist.
Statistiken hinzufügen (optional)
Sie können für Features, die zusammengefasst wurden, Statistiken berechnen.Für numerische Felder sind folgende Berechnungen möglich:
- Anzahl: Berechnet die Anzahl der Nicht-NULL-Werte.Sie kann für numerische Felder oder Zeichenfolgen verwendet werden. Die Anzahl von [NULL, 0, 2] beträgt 2.
- Summe: Die Summe der numerischen Werte in einem Feld. Die Summe von [NULL, NULL, 3] beträgt 3.
- Mittelwert: Der Mittelwert der numerischen Werte. Der Mittelwert von [0, 2, NULL] beträgt 1.
- Min: Der Minimalwert eines numerischen Feldes. Der Minimalwert von [0, 2, NULL] beträgt 0.
- Max: Der Maximalwert eines numerischen Feldes. Der Maximalwert von [0, 2, NULL] beträgt 2.
- Bereich: Der Bereich eines numerischen Feldes. Dieser wird durch die Subtraktion der Minimalwerte vom Maximalwert berechnet. Der Bereich von [0, NULL, 1] lautet 1. Der Bereich von [NULL, 4] lautet 0.
- Varianz: Die Varianz eines numerischen Feldes in einer Spur. Die Varianz von [1] beträgt Null. Die Varianz von [NULL, 1,0,1,1] beträgt 0,25.
- Standardabweichung: Die Standardabweichung eines numerischen Feldes. Die Standardabweichung von [1] ist Null. Die Standardabweichung von [NULL, 1,0,1,1] ist 0,5.
Für Zeichenfolgenfelder sind folgende Berechnungen möglich:
- Anzahl: Die Anzahl der Nicht-NULL-Werte.
- Beliebig: Diese Statistik ist eine auf dem Zufallsprinzip basierende Stichprobe eines Zeichenfolgenwertes im angegebenen Feld.
Einen ArcGIS Data Store zum Speichern der Ergebnisse auswählen
GeoAnalytics-Ergebnisse werden in einem Data Store gespeichert und als Feature-Layer in Portal for ArcGIS dargestellt. In den meisten Fällen sollten Ergebnisse im Data Store vom Typ "spatiotemporal" gespeichert werden, was gleichzeitig die Standardeinstellung ist. Manchmal empfiehlt es sich auch, Ergebnisse im Data Store vom Typ "relational" zu speichern. Die folgenden Gründe sprechen dafür, die Ergebnisse im Data Store vom Typ "relational" zu speichern:
- Sie können die Ergebnisse in portalübergreifender Zusammenarbeit verwenden.
- Sie sind in der Lage, Synchronisierungsfunktionen mit Ihren Ergebnissen zu aktivieren.
Der Einsatz des Data Stores vom Typ "relational" wird nicht empfohlen, wenn abzusehen ist, dass Ihre GeoAnalytics-Ergebnisse weiter zunehmen. Nutzen Sie in diesem Fall die Funktionen des Big Data Store vom Typ "spatiotemporal" zur Verwaltung von großen Datenmengen.
Name des Ergebnis-Layers
Der Name des Layers, der erstellt wird. Wenn Sie in einen ArcGIS Data Store schreiben, werden Ihre Ergebnisse in Eigene Inhalte gespeichert und der Karte hinzugefügt. Wenn Sie in eine Big-Data-Dateifreigabe schreiben, werden Ihre Ergebnisse in der Big-Data-Dateifreigabe gespeichert und ihrem Manifest hinzugefügt. Sie werden nicht der Karte hinzugefügt. Der Standardname basiert auf dem Werkzeugnamen und dem Namen des Eingabe-Layers. Wenn der Layer bereits vorhanden ist, kann das Werkzeug nicht ausgeführt werden.
Wenn Sie über das Dropdown-Feld Ergebnis speichern in in ArcGIS Data Store (Big Data Store vom Typ "relational" oder "spatiotemporal") schreiben, können Sie den Namen eines Ordners in Eigene Inhalte angeben, in dem das Ergebnis gespeichert wird.