Punkt-Cluster suchen
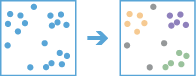
Das Werkzeug Punkt-Cluster suchen findet Cluster aus Punkt-Features im Datenrauschen des Umfelds basierend auf deren räumlicher Verteilung.
Eine Nichtregierungsorganisation untersucht beispielsweise eine bestimmte durch Schädlinge übertragene Krankheit. Sie verfügt über ein Punkt-Dataset, das Haushalte in einem Untersuchungsgebiet darstellt, von denen einige betroffen sind und andere nicht. Mithilfe des Werkzeugs Punkt-Cluster suchen kann ein Analyst die Cluster betroffener Haushalte ermitteln, um einen Bereich besser aufzeigen und mit der Behandlung und Vernichtung krankheitsübertragender Erreger beginnen zu können.
Wählen Sie den Layer aus, für den nach Clustern gesucht wird.
Der Punkt-Layer, in dem nach Clustern gesucht wird. Layer müssen sich in einem projizierten Raumbezug befinden oder einen Raumbezug für die Verarbeitung aufweisen, der unter Analyseumgebungen auf ein projiziertes Koordinatensystem festgelegt wurde.
Sie können nicht nur einen Layer aus der Karte auswählen, sondern auch unten in der Dropdown-Liste die Option Analyse-Layer auswählen auswählen, um zu Ihren Inhalten für ein Big-Data-Dateifreigabe-Dataset bzw. -Feature-Layer zu navigieren.
Zu verwendende Methode der Cluster-Bildung auswählen
Methode der Cluster-Bildung, mit der Cluster aus Punkt-Features vom Datenrauschen unterschieden werden. Sie können den Algorithmus "Definierte Entfernung" oder den Algorithmus "Automatische Anpassung" für die Cluster-Bildung verwenden.
"Definierte Entfernung (DBSCAN)" verwendet einen angegebenen Suchbereich, um dichte Cluster vom schwächeren Rauschen zu trennen. "Definierte Entfernung (DBSCAN)" ist die schnellere Methode, sollte aber nur dann verwendet werden, wenn mit einem sehr klaren Suchbereich gearbeitet werden kann, anhand dessen sich alle möglicherweise vorhandenen Cluster definieren lassen. "Definierte Entfernung (DBSCAN)" findet Cluster, die eine ähnliche Dichte aufweisen.
"Automatische Anpassung (HDBSCAN)" erfordert keine Angabe eines Suchbereichs, ist jedoch die zeitaufwändigere Methode. "Automatische Anpassung (HDBSCAN)" findet ähnlich wie "Definierte Entfernung (DBSCAN)" Cluster aus Punkten, verwendet jedoch unterschiedliche Suchbereiche, die Cluster mit variierender Dichte ermöglichen.
Minimale Anzahl von Punkten, die als Cluster gelten
Dieser Parameter wird je nach ausgewählter Methode der Cluster-Bildung auf unterschiedliche Weise verwendet:
- "Definierte Entfernung (DBSCAN)": Legt die Anzahl der Features fest, die sich in einer bestimmten Entfernung von einem Punkt befinden müssen, damit dieser als Ausgangspunkt für die Cluster-Bildung verwendet werden kann. Die Entfernung wird mit dem Parameter Suchbereich begrenzen auf definiert.
- Automatische Anpassung (HDBSCAN): Legt die Anzahl der Features fest, die sich in der Nachbarschaft jedes Punktes befinden (einschließlich des Punktes selbst), die beim Schätzen der Dichte berücksichtigt werden. Diese Zahl entspricht gleichzeitig der beim Extrahieren von Clustern zulässigen Mindestgröße für Cluster.
Suchbereich begrenzen auf
Bei Verwendung der definierten Entfernung (DBSCAN) ist dieser Parameter die Entfernung, in der sich die Minimale Anzahl von Punkten, die als Cluster gelten befinden muss. Dieser Parameter wird nicht verwendet, wenn die automatische Anpassung (HDBSCAN) als zu verwendende Methode der Cluster-Bildung ausgewählt ist.
Name des Ergebnis-Layers
Der Name des Layers, der erstellt wird. Wenn Sie in einen ArcGIS Data Store schreiben, werden Ihre Ergebnisse in Eigene Inhalte gespeichert und der Karte hinzugefügt. Wenn Sie in eine Big-Data-Dateifreigabe schreiben, werden Ihre Ergebnisse in der Big-Data-Dateifreigabe gespeichert und ihrem Manifest hinzugefügt. Sie werden nicht der Karte hinzugefügt. Der Standardname basiert auf dem Werkzeugnamen und dem Namen des Eingabe-Layers. Wenn der Layer bereits vorhanden ist, kann das Werkzeug nicht ausgeführt werden.
Wenn Sie über das Dropdown-Feld Ergebnis speichern in in ArcGIS Data Store (Big Data Store vom Typ "relational" oder "spatiotemporal") schreiben, können Sie den Namen eines Ordners in Eigene Inhalte angeben, in dem das Ergebnis gespeichert wird.