Find afvigelser
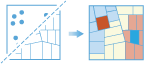
Værktøjet Find afvigelser kan bestemme, hvorvidt der er statistisk signifikante afvigelser i det rumlige mønster for dine data.
- Er der nogen afvigende områder i mønstret for dine data (forbrydelser, træer, trafikulykker)? Hvordan kan du være sikker på det?
- Har du rent faktisk opdaget en statistisk signifikant afvigelse (for forbrug, barnedødelighed, konsekvent høje testresultater) eller ville dit kort fortælle noget andet, hvis du ændrede symboliseringen?
Hver gang vi ser på kortet, er det naturligt for vores øjne og hjerner at forsøge at finde mønstre, også når det ikke findes nogen mønstre. Derfor kan det være svært at vide, om mønstrene i dine data er resultatet af en reel igangværende rumlig proces eller bare resultatet af tilfældigheder. Det er årsagen til, at forskere og analytikere bruger statistiske metoder som Find afvigelser (Anselin Local Moran's I) til at kvantificere rumlige mønstre. Når du finder statistisk signifikante afvigelser eller klyngedannelser i dine data, har du værdifulde oplysninger. Det at vide, hvor og hvornår afvigelser opstår, kan give vigtige oplysninger om de processer, der skaber de mønstre, du ser. Det næste trin ville være at undersøge, hvorfor ting adskiller sig i disse områder med afvigelser. At vide at f.eks. antallet af indbrud i boliger konsekvent er betydeligt højere i et bestemt område, der er omgivet af områder med betydeligt færre indbrud, er afgørende oplysninger, hvis du skal udarbejde effektive forebyggelsesstrategier, fordele begrænsede politiressourcer, iværksætte nabohjælpsprogrammer, godkende grundig kriminel efterforskning eller identificere potentielle mistænkte.
Vælg det lag, som der skal beregnes afvigelser for.
Det punkt- eller områdelag, som afvigelserne skal findes i.
Find afvigelser for
Denne analyse besvarer spørgsmålet: Hvor er de rumlige afvigelser i mine data?
Hvis dine data består af punkter, og du vælger Punktoptællinger, vil dette værktøj evaluere det spatiale arrangement af punktobjekter for at besvare spørgsmålet: Hvor danner punkterne uventede klynger eller bliver spredt ud?
Hvis du vælger et felt, vil dette værktøj evaluere det spatiale arrangement af værdier, der er knyttet til hvert objekt, for at besvare spørgsmålet: Hvor er der lave værdier, der er omgivet af høje værdier? Hvor er der høje værdier, der er omgivet af lave værdier?
Tæl punkter inden for
Standarden er at tælle punkter inden for et maskenet, der oprettes af værktøjet på grundlag af dine punktdata. Du kan også vælge at tælle punkter inden for et sekskantet gitter eller oprette et områdelag (disse ville typisk afspejle administrative rapporteringsdistrikter, såsom optællingsområder, kommunegrænser eller regioner) for at besvare følgende spørgsmål: I betragtning af antallet af punkter inden for hvert områdeobjekt findes der så steder med statistisk signifikante høje eller lave punkttællinger sammenlignet med de tilstødende områder?
Definér, hvor punkter er mulige
Du skal enten tegne eller oprette et lag, der definerer hvor hændelser er mulige, for at besvare spørgsmålet: Er der inden for områderne steder med usædvanligt høje eller lave punktkoncentrationer?
De områdeobjekter, som du tegner, eller de objekter i områdelaget, som du angiver, bør definere, hvor punkter muligvis kan opstå. For at tegne disse områder skal du klikke på knappen Tegn og derefter klikke på et sted på kortet for at oprette en områdeform. For at tegne flere områder skal du klikke på tegn-knappen igen og derefter klikke på et sted på kortet og fortsætte.
Dividér med:
Af og til vil du måske gerne analysere mønstre, der tager højde for underliggende distributioner. Hvis dine punkter f.eks. repræsenterer kriminalitet, vil division med det samlede befolkningstal resultere i en analyse af kriminaliteten pr. indbygger og ikke generelle kriminalitetstal. At vælge en attribut til division betegnes ofte som normalisering.
Valg af Esri Population vil udføre enrichment på hvert områdeobjekt med populationsværdier, der derefter vil blive brugt som divisionsattribut. Denne indstilling forbruger credits.
Optimér for
Du kan vælge at optimere hastigheden eller præcisionen.
Dette værktøj benytter permutationer til at bestemme, hvor meget dine datas rumlige mønster adskiller sig fra vilkårlige værdier. Hvis du øger antallet af permutationer, øges præcisionen, men behandlingstiden stiger også.
Tilsidesæt indstillinger
Værktøjet vil finde optimale indstillinger for standardværdierne for Cellestørrelse og Afstandsbånd baseret på dine datas karakteristika. Men hvis du har en bestemt Cellestørrelse eller et bestemt Afstandsbånd, som giver mening i forbindelse med din analyse, kan Tilsidesæt indstillinger benyttes til at indstille disse værdier.
Tilsidesæt indstillinger er også en nyttig funktion, når du kører analyse på forskellige datasæt, hvilket gør det muligt at bevare ensartede værdier for Afstandsbånd og Cellestørrelse på tværs af flere datasæt. Du kan derefter sammenligne resultaterne (f.eks. kan du sammenligne værdierne for fedme og sukkersyge – eller endda kriminalitet – for to forskellige år).
Cellestørrelse
Størrelsen på de gitterceller, der benyttes til at tælle punkter inden for.
Når du bruger et sekskantet gitter til optælling af punkter, anvendes denne afstand som højde på sekskanterne.
Afstandsbånd
Ethvert objekt analyseres i sammenhæng med de tilstødende objekter, der findes inden for den angivne afstand. Værktøjet vil beregne en standardafstand for dig, eller du kan benytte denne indstilling til at angive en bestemt afstand, som giver mening i forbindelse med din analyse.
Hvis du f.eks. er ved at undersøge mønstre for pendling, og du ved, at den gennemsnitlige transportafstand til arbejde er 15 miles, kan du benytte et afstandsbånd på 15 miles til din analyse.
Navn på resultatlag
Angiv et navn på det lag, som oprettes i Mit indhold og føjes til kortet. Dette resultatlag viser dig statistisk signifikante afvigelser med høje og lave værdier eller punkttællinger. Hvis navnet på resultatlaget allerede eksisterer, vil du blive bedt om at ændre det.
Ved hjælp af rullelisten Gem resultat i kan du angive navnet på en mappe i Mit indhold, hvor resultatet skal gemmes.