Reconstruct Tracks
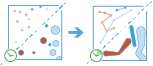
This tool works with a time-enabled layer of
either point or area features that represent an instant in time. It first
determines which features belong to a track using an identifier. Using the time at each location, the tracks are ordered sequentially and transformed into a line or area representing the path of movement over time. Optionally, the input may be buffered by a field, which will create an area at each location. These buffered points or input areas, are then joined sequentially to create a track as a area where the width is representative of the attribute of interest. Resulting tracks have a start and end time, which represent temporally the first and last feature in a given track. When the tracks are created, statistics about the input features are calculated and assigned to the output track. The
most basic statistic is the count of points within
the area, but other statistics can be calculated as well.
Features in time-enabled layers can be represented in one of two ways:
- Instant—A single moment in time
- Interval—A start and end time
For example, suppose you have GPS measurements of hurricanes every 10 minutes. Each GPS measurement records the hurricane's name, location, time of recording, and wind speed. With this information, you could create tracks for each hurricane using the name for track identification, and tracks for each hurricane would be generated. Additionally, you could calculate statistics such as the mean, max, and minimum wind speed of each hurricane, as well as the count of measurements within each track.
Using the same example, you could buffer your tracks by the wind speed. This would buffer each measurement by the wind speed field at that location, and join the buffered areas together, creating a area representative of the track path, as well as the changes in wind speed as the hurricanes progressed.
Choose features to reconstruct tracks from
The point or area layer that will be reconstructed into tracks. The input layer must be time-enabled with features that represent an instant in time. The layer must be in a projected coordinate system or the processing spatial reference must be set to a projected coordinate system using the Analysis Environments if a buffer is applied.
In addition to choosing a layer from your map, you can choose Choose Analysis Layer at the bottom of the drop-down list to browse to your contents for a big data file share dataset or feature layer.
Choose one or more fields to identify tracks
The fields that represent the track identifier.
As an example, if you were reconstructing tracks of hurricanes, you could use the hurricane name as the track field.
Choose method used to reconstruct tracks
Method used to join tracks and apply buffer (if applicable). The Planar method may calculate the results more quickly but will not wrap tracks around the international dateline or account for the actual shape of the earth when buffering. The Geodesic method will wrap tracks around the date line if required and apply a geodesic buffer to account for the shape of the earth.
Create an expression to buffer input features by (optional)
Equation used to calculate the buffer distance around input features. This equation can be generated using the buffer calculator and basic operations such as add, subtract, multiply, and divide are supported. Values are calculated using the analysis coordinate system. The layer must be in a projected coordinate system or the processing spatial reference must be set to a projected coordinate system using the Analysis Environments if a buffer is applied.
An equation like $feature.windspeed * 1000 would apply a buffer of 1,000 multiplied by the field windspeed. You may use more than one field in the buffer calculator.
You can also specify a track aware expression. For example, you could calculate the sum of field value windspeed for the current feature and previous two features with an equation like $track.field(windspeed).history(-3). At each location, the sum of the current windspeed, and previous two measurements would be calculated and buffered.
Select a time to split tracks by (optional)
Time used to split tracks. If input points or areas have a longer duration between them than the time split, they will be split into different tracks.
If you specify a time split and a distance split, tracks will be split when one or both conditions are met.
Imagine that you had point features representing aircraft flights, where the track field was the aircraft ID. This aircraft could make multiple trips and would be represented as one track. If you knew that there is a 1-hour break between the flights, you could use 1 hour as your track split, and each flight would be split into its own track.
Split tracks (optional)
You can split tracks using three different methods. You can use a combination of none, all, or some of the splitting methods.
Splits can be completed in the following ways:
- Based on a distance between inputs—If input points or areas have a wider distance between them than the specified distance, they will be split into different tracks. For example, if you specified a distance of 10 kilometers, sequential points greater than 10 kilometers would be separate tracks.
- Based on a time between inputs— If input points or areas have a longer duration between them than the time split, they will be split into different tracks. For example, if had point features representing aircraft flights, where the track field was the aircraft ID. This aircraft could make multiple trips and would be represented as one track. If you knew that there is a 1-hour break between the flights, you could use
1 houras your track split, and each flight would be split into its own track. - At defined time intervals—Split using regular intervals, specified by a time interval and a reference time. If you don't specify a reference time, Jan 1, 1970 will be used. For example, if you specified 1 year with a reference time of Feb 2, 1990 at 10:00, you would split tracks at Feb 2, 1990 at 10:00, Feb 2, 1991 at 10:00 and continue on in one year intervals.
If you specify multiple split options, tracks will be split when one or more conditions are met.
Select a distance to split tracks by (optional)
Distance used to split tracks. If input points or areas have a wider distance between them than the distance split, they will be split into different tracks.
If you specify a time split and a distance split, tracks will be split when one or both conditions are met.
Add statistics (optional)
You can calculate statistics on features that are summarized. You can calculate the following on numeric fields:
- Count—Calculates the number of nonnull values. It can be used on numeric fields or strings. The count of [null, 0, 2] is 2.
- Sum—The sum of numeric values in a field. The sum of [null, null, 3] is 3.
- Mean—The mean of numeric values. The mean of [0, 2, null] is 1.
- Min—The minimum value of a numeric field. The minimum of [0, 2, null] is 0.
- Max—The maximum value of a numeric field. The maximum value of [0, 2, null] is 2.
- Range—The range of a numeric field. This is calculated as the minimum values subtracted from the maximum value. The range of [0, null, 1] is 1. The range of [null, 4] is 0.
- Variance—The variance of a numeric field in a track. The variance of [1] is null. The variance of [null, 1,0,1,1] is 0.25.
- Standard deviation—The standard deviation of a numeric field. The standard deviation of [1] is null. The standard deviation of [null, 1,0,1,1] is 0.5.
You can calculate the following on string fields:
- Count—The number of nonnull strings.
- Any—This statistic is a random sample of a string value in the specified field.
Choose an ArcGIS Data Store to save results to
GeoAnalytics results are stored to an data store and exposed as a feature layer in Portal for ArcGIS. In most cases, results should be stored to the spatiotemporal data store and this is the default. In some cases, saving results to the relational data store is a good option. The following are reasons why you may want to store results to the relational data store:
- You can use results in portal-to-portal collaboration.
- You can enable sync capabilities with your results.
You should not use the relational data store if you expect your GeoAnalytics results to increase and need to take advantage of the spatiotemporal big data store's capabilities to handle large amounts of data.
Result layer name
The name of the layer that will be created. If you are writing to an ArcGIS Data Store, your results will be saved in My Content and added to the map. If you are writing to a big data file share, your results will be stored in the big data file share and added to its manifest. It will not be added to the map. The default name is based on the tool name and the input layer name. If the layer already exists, the tool will fail.
When writing to ArcGIS Data Store (relational or spatiotemporal big data store) using the Save result in drop-down box, you can specify the name of a folder in My Content where the result will be saved.