Aggregate Points
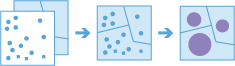
This tool works with a layer of point features and a layer of areas features. Input area features can be from a polygon layer or they can be square or hexagonal bins calculated when the tool is run. The tool first determines which points fall within each specified area. After determining this point-in-area spatial relationship, statistics about all points in the area are calculated and assigned to the area. The most basic statistic is the count of the number of points within the area, but you can get other statistics as well.
For example, suppose you have point features of coffee shop locations and area features of counties, and you want to summarize coffee sales by county. Assuming the coffee shops have a TOTAL_SALES attribute, you can get the sum of all TOTAL_SALES within each county, the minimum or maximum TOTAL_SALES within each county, or other statistics such as the count, range, standard deviation, and variance.
This tool can also work with data that is time-enabled. If time is enabled on the input points, then the time slicing options are available. Time slicing allows you to calculate the point-in-area relationship while looking at a specific slice in time. For example, you could look at hourly intervals, which would result in outputs for each hour.
For an example with time, suppose you had point features of every transaction made at various coffee shop locations and no area layer. The data has been recorded over a year and each transaction has a location and a time stamp. Assuming each transaction has a TOTAL_SALES attribute, you can get the sum of all TOTAL_SALES within the space and time of interest. If these transactions are for a single city, we could generate areas that are 1-kilometer grids and look at weekly time slices to summarize the transactions in both time and space.
Choose a layer containing points to aggregate into areas
The point layer that will aggregate into the areas. Point layers that are aggregated into Square or Hexagon bins must have the processing spatial reference set to a projected coordinate system using the Analysis Environments.
In addition to choosing a layer from your map, you can choose Choose Analysis Layer at the bottom of the drop-down list to browse to your contents for a big data file share dataset or feature layer.
Choose an area layer to aggregate into
The areas that the point layer will be aggregated into. You can choose between an area layer that you provide or bins that are generated when the tool runs. When generating bins, for Square, the number and units specified determine the height and length of the square. For Hexagon, the number and units specified determine the distance between parallel sides.
Analysis using Square or Hexagon bins requires a projected coordinate system. You can set the Processing coordinate system in Analysis Environments. If your processing coordinate system is not set to a projected coordinate system, you will be prompted to set it when you Run Analysis .
Choose the area layer to aggregate into
The area layer to which the points will be aggregated. Any points that fall within the boundaries of areas in this layer will be counted and optionally summarized using your choice of statistics.
Either Bin Size for bins or Area Layer must be set.
Choose a distance to generate bins and aggregate into
The distance used to generate bins to aggregate your input points into. For a square bin, the size represents the height of the square. For hexagon, the size represents the height of the hexagon (from parallel sides).
Either Bin Size for bins or Area Layer must be set.
Aggregate using time steps (optional)
If time is enabled on the input point layer and it is of type instant, you can analyze using time stepping. There are three parameters you can set when you use time:
- Time step interval
- How often to repeat the time step
- Time to align the time steps to
For example, if you have data that represents a year in time and you want to analyze it using weekly steps, set Time step interval to 1 week.
For example, if you have data that represents a year in time and you want to analyze it using the first week of the month, set Time step interval to 1 week, How often to repeat the time step to 1 month, and Time to align the time steps to to January 1, at 12:00 am.
Time step interval
The interval of time used for generating time steps. Time step interval can be used alone or with the How often to repeat the time step or Time to align the time steps to parameter.
For example, if you want to create time steps that take place every Monday from 9:00 a.m. until 10:00 a.m., set Time step interval to 1 hour, How often to repeat the time step to 1 week, and Time to align the time steps to to 9:00:00 a.m. on a Monday.
How often to repeat the time step
The step used for calculating a time step. How often to repeat the time step can be used alone, with Time step interval, with Reference Time, or with both Time step interval and Time to align the time steps to.
For example, if you want to create time steps that take place every Monday from 9:00 a.m. until 10:00 a.m., set Time step interval to 1 hour, How often to repeat the time step to 1 week, and Time to align the time steps to to 9:00:00 a.m. on a Monday.
Time to align time steps to
The date and time used to align time slicing. Time stepping will start at and continue backward from this time. If no reference time is selected, time stepping will align to January 1st, 1970.
For example, if you want to create time steps that take place every Monday from 9:00 a.m. until 10:00 a.m., set Time step interval to 1 hour, How often to repeat the time step to 1 week, and Time to align the time steps to to 9:00:00 a.m. on a Monday.
Add statistics (optional)
You can calculate statistics on features that are summarized. You can calculate the following on numeric fields:
- Count—Calculates the number of nonnull values. It can be used on numeric fields or strings. The count of [null, 0, 2] is 2.
- Sum—The sum of numeric values in a field. The sum of [null, null, 3] is 3.
- Mean—The mean of numeric values. The mean of [0, 2, null] is 1.
- Min—The minimum value of a numeric field. The minimum of [0, 2, null] is 0.
- Max—The maximum value of a numeric field. The maximum value of [0, 2, null] is 2.
- Range—The range of a numeric field. This is calculated as the minimum values subtracted from the maximum value. The range of [0, null, 1] is 1. The range of [null, 4] is 0.
- Variance—The variance of a numeric field in a track. The variance of [1] is null. The variance of [null, 1,0,1,1] is 0.25.
- Standard deviation—The standard deviation of a numeric field. The standard deviation of [1] is null. The standard deviation of [null, 1,0,1,1] is 0.5.
You can calculate the following on string fields:
- Count—The number of nonnull strings.
- Any—This statistic is a random sample of a string value in the specified field.
SpatialReference (wkid)
This is a temporary parameter for prerelease to set the processing spatial reference. Many big data tools require that a projected coordinate system is used as the spatial reference for processing. By default, the tool will use the input coordinate system but will fail if it's a geographic coordinate system. To set a projected coordinate system, enter the WKID. For example, Web Mercator would be entered as 3857.
Choose an ArcGIS Data Store to save results to
GeoAnalytics results are stored to an data store and exposed as a feature layer in Portal for ArcGIS. In most cases, results should be stored to the spatiotemporal data store and this is the default. In some cases, saving results to the relational data store is a good option. The following are reasons why you may want to store results to the relational data store:
- You can use results in portal-to-portal collaboration.
- You can enable sync capabilities with your results.
You should not use the relational data store if you expect your GeoAnalytics results to increase and need to take advantage of the spatiotemporal big data store's capabilities to handle large amounts of data.
Result layer name
The name of the layer that will be created. If you are writing to an ArcGIS Data Store, your results will be saved in My Content and added to the map. If you are writing to a big data file share, your results will be stored in the big data file share and added to its manifest. It will not be added to the map. The default name is based on the tool name and the input layer name. If the layer already exists, the tool will fail.
When writing to ArcGIS Data Store (relational or spatiotemporal big data store) using the Save result in drop-down box, you can specify the name of a folder in My Content where the result will be saved.